




用「晨间简报」学会 Codex:六个可复制的使用层级
2026-05-20
2026-05-26 0
过去几年,
世界模型
的出现,正在推动
人工智能
加速从虚拟空间走向物理世界。和传统大语言模型相比,世界模型可以更好理解现实世界的物理规律,实现对真实世界更好的预演和推理。智能汽车是
AI
从虚拟走向物理世界的天然载体,也是世界模型落地的最佳场景之一。
今天,小米汽车正式发布
Xiaomi
Auto
World Model
全新框架,为业界辅助驾驶世界模型提供了新的框架路径,推动行业从
“
场景感知
”
向
“
认知推演、场景进化
”
的高阶形态跃迁。
这是小米首次将三维重建与视频生成深度耦合的一体化架构,以「重建锚定几何、生成填补想象」的新范式,打破行业长期采用的重建、生成独立拆分路线。在 Waymo、nuScenes 等主流基准测试中全面取得 SOTA,并已在小米汽车合成数据、仿真测试、智能座舱三大核心场景完成业务落地。
01
世界模型:辅助驾驶的「大脑预演系统」
想象一下:高速上前方突然滚落一个轮胎,要让辅助驾驶应对这类突发场景,它必须“见过”足够多类似的情况。但现实中不可能穷举所有可能——暴雨中冲出的行人、高速上的落石、逆行车辆,这些长尾场景发生概率极低,却可能致命。
因此,世界模型应运而生——它根据历史和当下的观测,预测周围环境接下来会如何演化。对辅助驾驶而言,这意味着车辆不仅能“看见”当下,还能“想象”未来。
目前,世界模型有两条主要技术路线——
重建(WorldRec)
与
生成(WorldGen)
,各有明确的优势与短板:
重建从多视角观测恢复几何精确的 3D 场景,优势是高保真、强一致性,但只能还原已见内容,缺乏想象能力
;
生成通过扩散模型直接预测未来画面,能
”
想象
”
未观测视角和未发生场景,但缺乏显式 3D 结构,且长时序下容易漂移失真。
那二者天然互补,能不能串联使用呢?
现有方法往往把它们简单串联——先重建一个场景,再喂给生成模型当条件。这种简单的拼接有一个根本矛盾:
重建追求的是确定性的几何保真,生成追求的是分布层面的多样性,目标函数在设计上方向并不一致
。
最终只会让二者各自的优势都打折扣。
02
小米的答案:重建+生成,一个框架全搞定
而 Xiaomi
Auto
World Model
则是提
出一
个全新的整合框架,将重建模块(WorldRec)与生成模块(WorldGen)深度耦合,让两者在结构上互相约束:
重建侧给生成“打地基”
:
WorldRec 维护一个随观测增量扩展的 4D Gaussian 全局表示,把这个 3D 几何投影到自车视角后作为渲染先验喂给生成模型。这意味着生成模型在已观测区域不再“自由发挥”,而是被几何约束锁住——车道结构、建筑位置、相机间的一致性都由重建来兜底,生成只负责补全光照、纹理和未观测区域。
生成侧给重建“扩边界”
:
在重建覆盖不到的时空区域(未来帧、未观测视角、遮挡区),WorldGen 用生成能力把内容补出来,让整个世界模型不再受限于“开过的路”。
两者共同压制长时序漂移
:
重建提供的确定性几何先验持续校正生成过程,从根源上抑制曝光偏差带来的累积误差,让一分钟级别的长视频生成依然保持稳定。
Xiaomi
Auto
World Model 效果展示
重建提供 3D 几何作为结构化锚点,约束生成过程的稳定性;生成则把预测能力延伸到观测之外,弥补重建的边界。两者形成闭环、互相增益,从三个关键维度实现了“1+1>2”的协同增益:
高稳定性
:
WorldRec 的确定性几何约束,有效抑制长时序自回归中的误差累积与内容漂移。
高一致性
:
4D 场景表征作为跨帧共享记忆,确保不同时刻、不同视角下场景内容全局一致。
高真实性
:
WorldGen 以 WorldRec 渲染的 RGB 图像为几何骨架,使合成内容既符合物理布局,又贴近真实传感器观测,显著缩小了“仿真-现实”的领域鸿沟。
▍
WorldRec:从「逐像素」到「稀疏锚点」
要进一步理解重建与生成如何协同,首先要看重建侧做了什么。
当前主流的前馈式三维重建方法普遍采用“逐像素预测高斯”的范式——每张图独立产出一套高斯点,再硬拼到三维空间里,导致
“
鬼影
”
、分层和上亿高斯的渲染开销。
我们认为,问题的根源不在融合策略不够好,而在表征本身没有“约束同一个三维点必须收敛为同一个高斯”的机制。
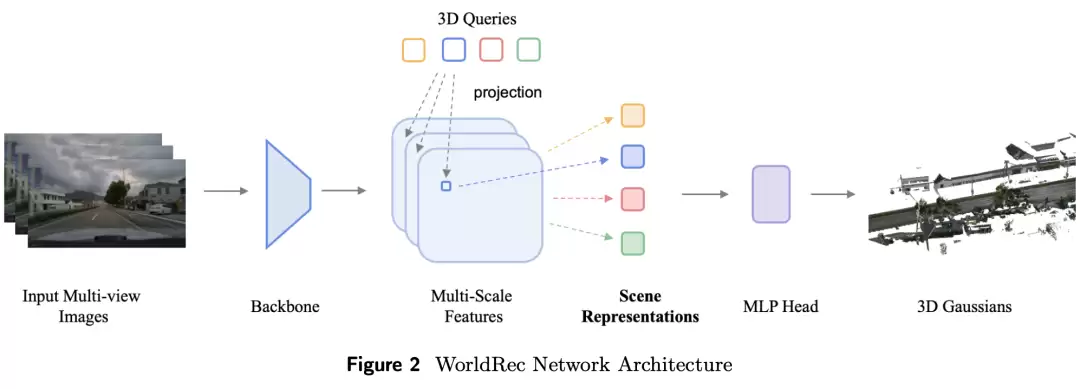
基于这一思考,我们 WorldRec 模块的核心思路是把场景表示从“稠密像素”换成
稀疏的三维查询点,实现了重建10秒视频仅需10秒的高效率
:
稀疏三维锚点表征
:
用稀疏查询点替代上亿稠密高斯,每个锚点对应一个唯一的三维位置,从源头消除多视角冲突。
多视角多时刻特征聚合
:
每个锚点主动到多个相机、多个时刻的图像里采集特征证据,形成跨视角一致的场景表示。
可见性加权融合
:
遮挡、反光的视角自动降权,干净视角自动加权,让模型聚焦在最可靠的观测上。
W
orldRec 的10s快速重建效果展示
▍ WorldGen:从「逐帧修图」到「自由绘画」
有了精确的 3D 场景作为锚点,生成侧的工作就变得清晰:在重建覆盖不到的时空区域——未来帧、未观测视角、遮挡区——把内容补出来。
WorldGen 不再依赖“逐帧修图”,而是能够“自由绘画”的生成引擎。仅需4步去噪,0.19秒就可以生成一帧,支持最长1分钟视频。
它的解法是通过两阶段训练:
第一阶段用全双向时序注意力进行预训练,让模型同时看到全部帧,建立对驾驶场景时空分布的全局理解;
第二阶段进入因果微调,用教师强制
(Teacher Forcing)
切换因果注意力,再用 ODE 蒸馏把去噪步数从50步压到4步提速12倍,最后用分布匹配蒸馏解决暴露偏差,从根源上抑制长序列漂移。
除了训练逻辑的优化,WorldGen 的真正价值在于它应对真实世界长尾场景的能力。无论是罕见的动物闯入——马匹、老虎突然出现在路面,还是极端天气——暴雨、大雪、浓雾,WorldGen 都能高质量地生成这些高危险性、低发生率的场景,为辅助驾驶感知模型的训练提供了宝贵的虚拟数据。
WorldGen 的极端场景效果
03
全面领先,已落地三大场景
技术上的1+1>2,最终要落到实际效果里才算数。
在重建领域,Xiaomi
Auto
World Model WorldRec 在公开的 Waymo 数据集上,全面领先此前 SOTA 方法 DGGT,PSNR(衡量重建精度的核心指标,越高越好)达到28.48,超出 DGGT 约1个点。更重要的是,在 nuScenes 零样本泛化测试中,对比 SOTA 方法,依然保持领先,说明它不只在特定的数据集上表现好,对新场景也有很强的适应能力。
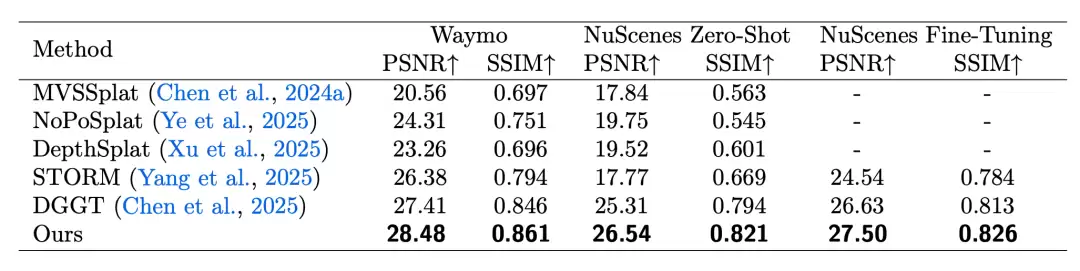
在生成领域,Xiaomi
Auto
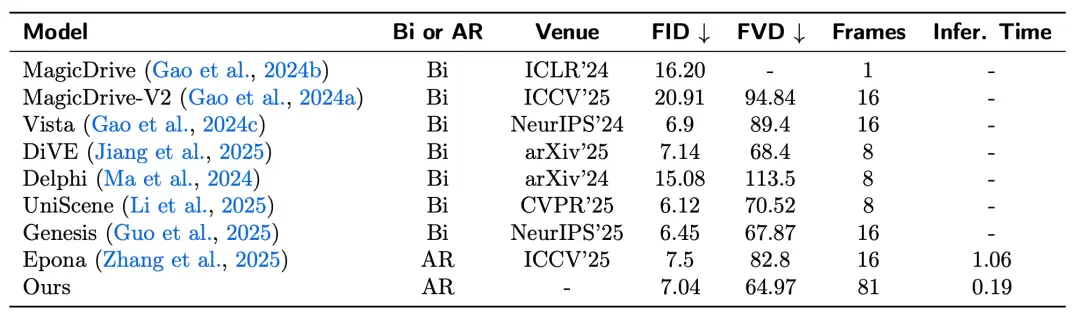
World Model 在 H20 GPU 上,单视角生成速度达到0.19秒/帧,三视角为0.46秒/帧,对比同为自回归方法的 Epona(1.06秒/帧)快了5.6倍。并且,WorldGen 还支持高达81帧的连续生成(10Hz/30Hz,最长可达1分钟),而大多数公开基线模型仅能生成8-16帧。
同时,在权威的 nuScenes 数据集上,WorldGen 取得了 FVD 64.97 和 FID 7.04 的成绩,FVD 指标超越了所有对比的同类双向与自回归方法模型,保持了极具竞争力的 FID。
而 Xiaomi
Auto
World Model 也已经在小米汽车三大实际场景中落地:
合成数据 生成
:
已交付超过10万 clips 高质量合成数据,直接用于感知模型训练,提升车辆在危险场景下的识别能力。
仿真测试
:
构建闭环仿真环境,优化测试效率,完备测试规范,可在仿真中复现真实事故进行定向优化。
辅助驾驶学堂
:
利用世界模型动态生成第一人称驾驶教学视频,用户面对复杂路况时,系统以生成式视频展示正确操作。目前已经上线小米全车型的辅助驾驶学堂 - 实景模拟场景,欢迎大家体验。
从“看见”到“想象”,Xiaomi
Auto
World Model 正在为辅助驾驶构建一个可以信赖的“数字平行世界”。这不只是实验室里的 SOTA,更是已经在小米汽车业务中运转的生产力。
下一步,小米汽车将继续探索预训练与闭环训练范式,推动端到端模型的认知能力跃升。
更多技术细节,请访问技术主页与论文:
技术主页:https://JointWM.github.io/
论文链接:https://arxiv.org/pdf/2605.18137
END
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]