2026-05-30 0
大模型时代的竞争焦点正转向数据质量,本文深度解析如何通过精细化数据治理释放小模型的惊人潜力。
Datawhale干货
作者:面壁智能团队
在人工智能领域,1B参数模型的表现差异往往源于数据质量而非架构设计。当公开语料库逐渐耗尽,如何从存量数据中提炼高密度知识成为关键突破点。
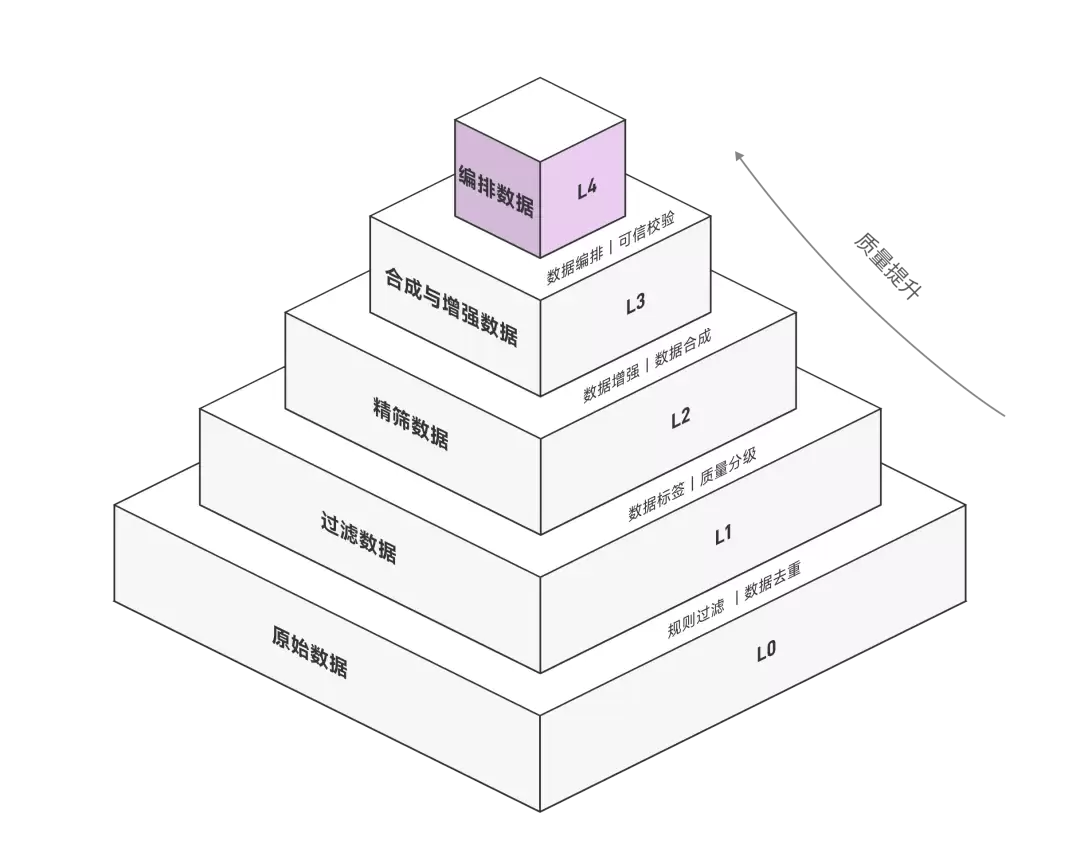
传统数据处理流程简单粗暴,难以充分发挥数据价值。面壁智能提出的五级治理体系,将数据加工深度与训练阶段精准匹配,实现成本与收益的最优平衡。
L0 原始数据:包含PB级原始网页内容,未经实质处理,存在大量噪声。
L1 过滤数据:通过规则完成基础去重和格式规范,质量参差不齐。
L2 精筛数据:采用模型打分筛选出高信息密度内容,领域指向明确。
L3 合成数据:经过多风格改写和人工标注,适合高阶训练阶段使用。
L4 编排数据:完成可信校验和知识编排,直接支持RAG应用。
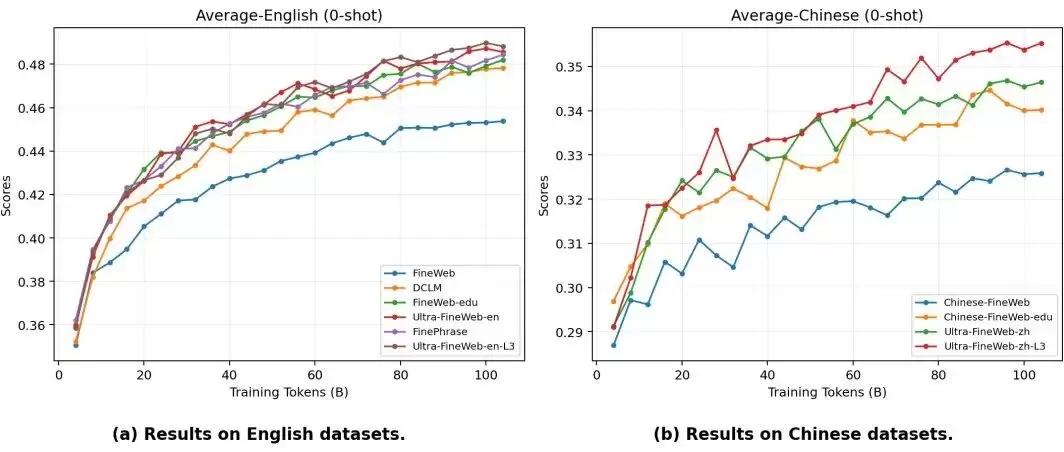
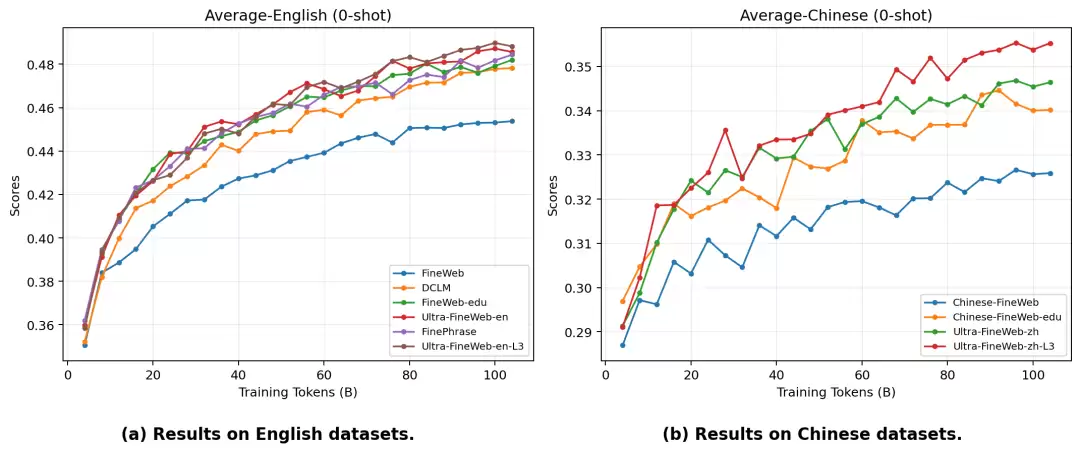
这套体系在数学领域验证效果显著,UltraData-Math仅用100B Tokens就在多个评测中超越主流模型,证实了L3数据对复杂推理的提升作用。
Ultra-FineWeb-L3通过深度加工将普通网页转化为结构化学习材料。借助MiniCPM4和Qwen3模型,将平铺直叙的内容重构为问答形式,大幅提升知识密度。
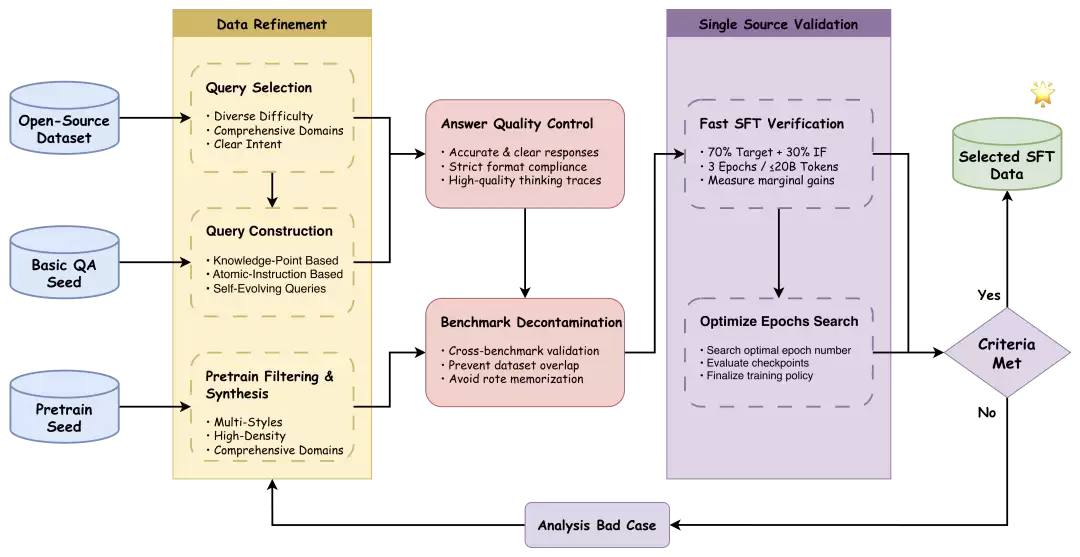
UltraData-SFT-2605突破性地同时包含常规问答和完整思维链样本。其全流程透明化的质量治理体系,为社区提供了可复现的数据工程范式。
MiniCPM5-1B的成功印证了分级数据的价值。通过精准配置不同层级数据,这款端侧模型在多个评测中超越同类产品,展现出小模型的巨大潜力。
除数据集外,面壁智能还开源了全套数据治理工具,包括单一数据验证、Epoch搜索等组件,支持开发者构建自己的数据流水线。
精细化数据治理正在重塑行业格局,通过高质量数据赋能小模型,为终端设备带来更高效的AI解决方案。

这场数据革命正在证明:当治理方法得当,小模型同样能迸发出惊人的智能潜力,开启端侧AI的全新可能。
大家都在看
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]




