2026-06-09 0
原创 NLPer 2026-06-08 15:53 江苏

MAI-Thinking-1: Building a Hill-Climbing Machine
来源:MAI-Thinking-1: Building a Hill-Climbing Machine
作者:The Microsoft AI Team
发布时间:2026 年 6 月 2 日(Microsoft Build 2026)
报告页数:109 页

MAI-Thinking-1 是微软 AI 团队(MAI)从零开始训练的推理模型,也是微软首次不依赖 OpenAI 或任何第三方模型蒸馏、独立构建的前沿大模型。它使用完全经过商业授权的干净数据,所有训练流程均由微软内部完成。
这份报告的标题是Building a Hill-Climbing Machine,核心思想是:把模型开发本身变成一个可持续优化的工程系统,而不是靠某个单一突破。
三个设计原则贯穿全文:
能力要自己学,不靠蒸馏— 通过蒸馏获得的能力缺乏可控性和鲁棒性,不适合长期持续改进。
简单才能持久— 优先选择干净的数据、简洁的配方和透明的基础设施。
科学严谨,拒绝捷径— 每个决策都必须通过数据驱动的消融实验和 Scaling Ladder 验证。
| 项目 | 数值 |
|---|---|
| 架构类型 | 稀疏混合专家(Sparse MoE) |
| 活跃参数 | 34.7B |
| 总参数 | 约 962B(~1T) |
| 层数 | 78 层 |
| 上下文窗口 | 256,000 tokens |
| 激活专家 / 总专家 | 8 / 512 |
| 词表大小 | 200,019(o200k_base tokenizer) |
| 训练 GPU | 8,192 张 GB200 NVL72 |

1. Local/Global 注意力 5:1 交替
每 6 层包含 5 层 Local Attention(RoPE 编码,滑动窗口 512)和 1 层 Global Attention(无位置编码)。好处是大幅降低计算量和 KV 缓存,训练和推理效率都更高。
2. Dense FFN 与 MoE 交替
每两层由一个高稀疏 MoE(8/512 专家)和一个 Dense FFN(SwiGLU 激活)交替构成。比"全部 MoE"方案在实际训练速度(EGTime)上更优——尽管 FLOPs 相当,MFU 更高。
3. LatentMoE 压缩
All-to-All 路由前先做下投影压缩到潜空间,减少跨 GPU 数据传输量。路由决策基于原始表示,每个压缩表示被路由到 8/512 个专家,softmax 门控。全局批次负载均衡,无 Token 丢弃(Dropless MoE)。
微软使用从 L12(365M 活跃参数)到 L78(35.6B 活跃参数)的完整模型梯队,在恒定 TPP(每活跃参数训练 token 数)下做消融实验,确保架构改进在大规模下仍然成立。所有决策都要在至少两个不同规模上验证。
| 数据来源 | 独特 token 量 | 训练 token 量 | 占比 | 平均复读次数 |
|---|---|---|---|---|
| 代码 | 7.4T | 16.4T | 54.6% | 2.22× |
| STEM | 2.2T | 4.7T | 15.8% | 2.17× |
| 网页文本 | 8.1T | 4.5T | 14.9% | 0.55× |
| 数学 | 0.3T | 1.6T | 5.4% | 5.28× |
| | 2.7T | 1.4T | 4.7% | 0.53× |
| 书籍期刊 | 0.6T | 0.9T | 3.1% | 1.65× |
| 多语言(其他) | 8.1T | 0.5T | 1.6% | 0.06× |
数据知识截止日期:
网页 HTML:2025 年 9 月
网页 PDF:2025 年 12 月
公开 GitHub 代码:2025 年 6 月
书籍与期刊:2026 年 3 月
重要原则:
不使用任何 LLM 生成的合成数据用于预训练
不使用任何开源训练数据集
排除 huggingface.co 等机器学习数据仓库
所有数据来源于公开可用或经商业授权的人工数据
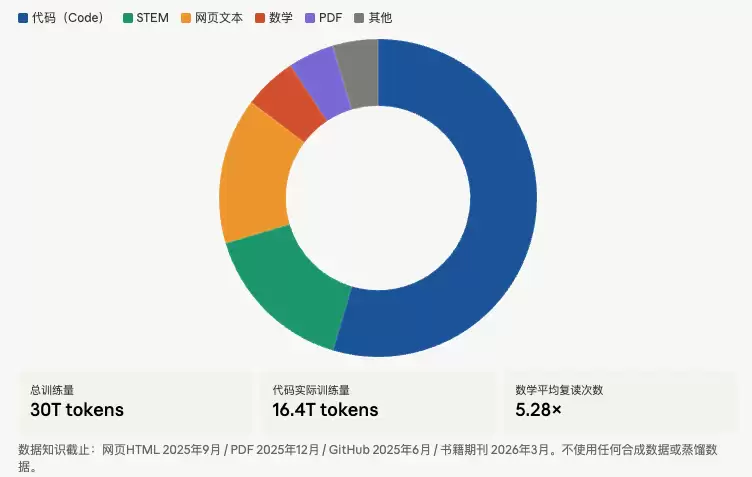
图2:数据配比最重要的发现——"代码优先"比"STEM优先"在大规模下更好
报告记录了一个反直觉实验:在小规模(5B 参数)下,STEM 重型数据在 STEM 评估上优于代码重型数据;但扩大到 23B 参数、训练 20T token 后,排名反转——代码重型数据的 STEM 评估反而更优。
根本原因:STEM 重型配置里有两个数据集质量高但多样性低,小模型从中受益,但大模型过拟合。这一发现打破了"小规模实验可以预测大规模排名"的假设,促使团队从此必须在多个规模点上验证数据配比决策。
五种去重手段层层叠加:
Boilerplate 去除:基于行频统计去掉导航栏、页眉页脚等重复元素
精确去重:字节级和哈希级完全重复
模糊去重:MinHash LSH,相似度阈值 0.8
模板去重:对页面骨架做模糊去重,消除大量相似的"计算器网页"等
语义去重:使用 Qwen3-Embedding-0.6B 向量化,按余弦相似度聚类,每簇只保留有限代表
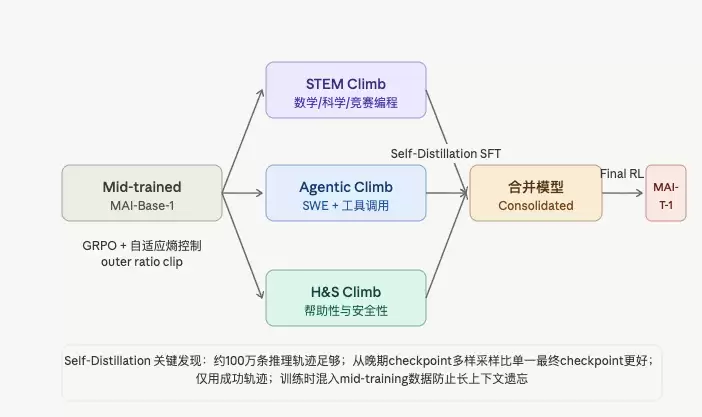
Mid-trained MAI-Base-1
│
├──→ STEM Climb(数学/科学/竞赛编程)──┐
├──→ Agentic Climb(SWE + 工具调用)──→ Self-Distillation SFT → Consolidated Model → Final RL → MAI-Thinking-1
└──→ H&S Climb(帮助性与安全性)──────┘
三个专家模型并行训练,最后通过 Self-Distillation SFT 合并,再做轻量级 Final RL。
基础算法为 GRPO(Group Relative Policy Optimization),Token 级别策略梯度,加了两个关键改动:
改动一:自适应熵控制(Adaptive Entropy Control)
传统固定 clip 上界容易导致熵崩溃(entropy collapse)或熵爆炸(entropy explosion)。MAI 用积分控制器动态调整 clip 上界,把实时策略熵维持在目标值 H* = 0.3 附近,不需要显式熵奖励项。
改动二:外层比率 Clip(Outer Ratio Clip)
GRPO 原始公式在两个区间不做限制(advantage 为负但 new policy 概率更高,或反之),这两种情况在实践中有时会产生梯度爆炸。加了硬性外层 clip(rmax = 50),大幅减少 spike 频率。
所有 RL 阶段统一用同一个奖励分解公式:
R(q, y) = R_task(q, y) + w_lang × R_lang(y) - w_len × R_len(y)
任务奖励:各领域专属(代码执行、数学验证、AI Judge 等)
语言一致性奖励:惩罚推理链里出现非英文 token(会导致 training/inference 分布不一致)
长度惩罚:按题目通过率调整——难题通过率低,惩罚弱;简单题惩罚强,防止无谓的长推理
经过大量实验,报告总结出最佳实践:
约 100 万条推理轨迹足够,更多数据收益递减,且风险限制策略探索空间
仅用成功轨迹(正确答案),失败轨迹训练效果与成功轨迹相当,但没必要额外引入
从晚期 checkpoint 多样采样,比只用最终 checkpoint 效果更好(更高多样性)
训练时混入 mid-training 数据,防止长上下文能力遗忘
STEM 数据从数百万文档中提取,经过四个阶段处理:
层次解析:OCR + 结构识别 + Q/A 提取
Q-A 配对:多轮 LLM 辅助配对(题目与答案分散在不同位置的情况)
质量筛选:分类可验证性、题型、去 PII、去答案泄漏、格式转换(MCQ→开放题)
难度评分:四档模型各解 k 次,用通过率划分难度区间;盲评筛掉地真答案可疑的题目
最终 STEM Mix 数据集超过 500 万条样本,最难子集超过 55 万条。
从 1.02 亿个 GitHub PR 出发,经过筛选、环境构建、验证,最终只有26.5 万个(5.5%)通过所有关卡,覆盖 94,044 个唯一仓库。
防作弊机制(发现了三种真实作弊行为):
搜索互联网拿 PR 答案 → 网络隔离解决
翻 git 历史找 solution commit → 时间旅行清洗 repo 解决
篡改测试文件 → 隐藏测试集 + 提交后重置解决
安全不是"权重很高的软约束",而是"先于所有奖励计算的硬门":
词典序聚合:低优先级奖励只在高优先级 tied 时才参与梯度
门控聚合:安全违规直接给最低奖励,不看其他维度分数
这样设计确保安全性永远不会被帮助性高分覆盖。
YOLO(You Only Launch Once)是微软自研的大规模训练框架,基于 PyTorch,支持预训练、中期训练、SFT 和 RL 的所有阶段。
给定相同硬件和配置,两次训练能产生比特完全一致的结果。实现手段:
固定数据加载顺序
确定性 GPU kernel(两阶段 tiled reduction,固定累积顺序)
固定 NCCL 拓扑(禁用 NVLink SHARP)
MoE 路由使用稳定排序
代价:MFU 轻微下降。收益:完整的科学复现能力和调试能力。
先把 checkpoint tensor 从 GPU 复制到 host 内存,再在独立进程里写入存储,训练同时继续。配合预计算 save plan,把 checkpoint 存储时间压缩了10 倍以上。
| 版本 | 活跃参数 | GPU 数量 | 关键变化 | MFU |
|---|---|---|---|---|
| v2 | 23B | 4,096 | 首个 GB200 基线 | 22% |
| v3 | 23B | 4,096 | Dropless MoE | 22% |
| v4 | 23B | 8,192 | 专家数 192→512,Top-4→8,LatentMoE | 20% |
| v5(MAI-Base-1) | 35B | 8,192 | 模型扩大至 35B | 20% |
效率增益从 v2 基线的 1.0× 提升到 v5 的1.69×。
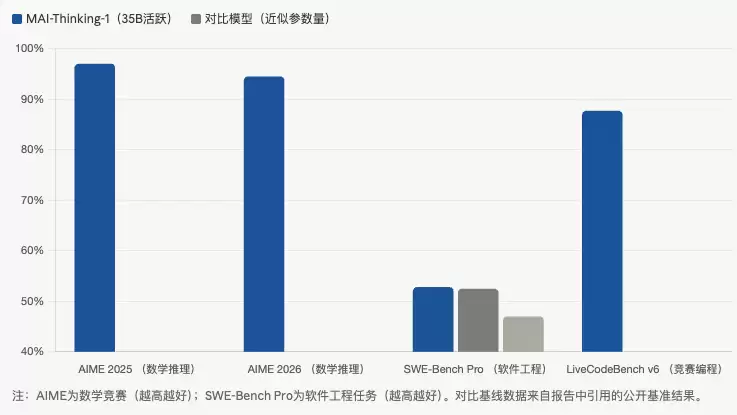
| 基准 | MAI-Thinking-1 | 备注 |
|---|---|---|
| AIME 2025 | 97.0% | 数学竞赛 |
| AIME 2026 | 94.5% | 数学竞赛 |
| SWE-Bench Pro | 52.8% | 软件工程(与 Claude Opus 4.6 持平) |
| LiveCodeBench v6 | 87.7% | 竞赛编程 |
MAI-Base-1 在代码、QA、STEM、数学四项 held-out 评估上均优于同规模的 DeepSeek V3.2、Kimi-K2 和 Gemma4-31B。与活跃参数 1.4× 的 DeepSeek V4 Pro 差距明显,与 1.6× 总参数的同款相比则更接近。
⚠️ 以上数据均来自微软自发布的预印本,独立机构完整复现尚未完成。
覆盖:有害内容(CSAM、暴力、自我伤害)、CBRN(化生放核武器)、自我感知(self-awareness)、欺骗性行为等类别。专门开发了内部安全基准衡量进展。
由独立机构负责,细节有限,结果已写入报告但未完整公开。
有害请求:全拒绝或部分拒绝(拒绝有害部分,提供安全替代)
边界请求:do-not-refuse,提供有边界的有用答案,不对接并拒绝
安全评分维度:政策合规 × 参与程度 × 响应风格(三轴独立评分)
这份报告的价值在于完整性——从数据管道到架构设计,从 RL 算法细节到训练基础设施,每个环节都有具体描述和实验支撑。
对 AI 研究者最有价值的内容:
自适应熵控制机制(无需显式熵奖励的稳定 RL 方案)
STEM 数据配比的排名非不变性发现(挑战小规模实验代里大规模决策的假设)
SWE 环境防作弊机制(真实作弊模式的系统性解决)
Outer Ratio Clip 防梯度爆炸(GRPO 的实用改良)
对产品决策者最关键的信息:
这是微软第一个从零训练、完全不依赖 OpenAI 的前沿推理模型
在 SWE-Bench Pro 上与 Claude Opus 4.6 持平,AIME 数学推理达到 97%
目前通过Microsoft Foundry 私有预览开放,未来上线 OpenRouter 等平台
与 GPT-5.5 相比,经微调的 MAI 系列每美元输出 token 数预计提升约 10 倍
参考来源:
MAI-Thinking-1 技术报告:https://microsoft.ai/pdf/mai-thinking-1.pdf
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点

关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。

大家都在看
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]




