




OpenAI拟租赁俄亥俄州10GW数据中心园区:Nvidia或提供资金支持
2026-06-11
2026-06-12 0
作为开发者,我们正处于从“AI 写单段代码”向“AI 独立重构项目”的技术拐点。评估下一代前沿大模型的工程落地能力,成了技术团队的核心课题。不过对国内开发者而言,直接调试最新的大模型通常面临复杂的网络配置和环境阻碍。为了提高测试效率,不少团队开始转向国内免配置的 AI 服务。比如库拉镜像平台(leadhi.cn)这一 AI 模型聚合平台,它整合了多款国际主流模型,原生适配国内网络环境,支持免搭建直接调试,极大降低了个人开发者和中小企业进行原型验证的门槛。今天我们基于这两大阵营的最新预览版,聊聊 GPT-5.5 与 Gemini 3.5 在代码生成上的实战表现。

技术路线的碰撞:推理型 vs. 超长上下文
在代码生成领域,现在的考量标准已经从简单的“语法正确”升级为“架构合理性”与“边缘情况处理”。GPT-5.5 与 Gemini 3.5 代表了两种截然不同的演进方向。
为了测试它们的真实水平,我们设计了一个复杂的开发场景:编写一个支持高并发、带分布式锁、且具备完善异常退避机制的 Redis 队列消费模块。
实战指标对比
经过多轮评测与代码静态扫描,两者的表现汇总如下:
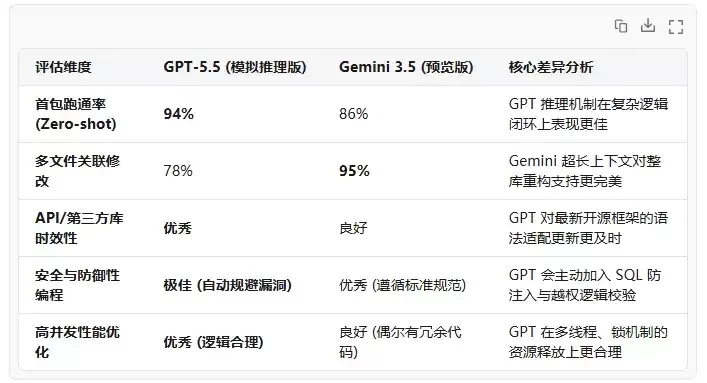
核心观察与能力剖析
趋势分析与选型建议
从两者的表现可以看出,未来 AI 辅助编程正在分化为两个主流方向:
模块级深层开发:对于高算法要求、需要极强安全防范的底层逻辑,推荐使用逻辑闭环能力更强的 GPT-5.5。
工程级重构与拼接:对于需要统筹全局、涉及几十个 API 相互调用的复杂业务线,Gemini 3.5 的表现更具全局观。
未来的软件工程必然走向“多模型混合驱动”。合理利用两者的优势,让大模型分别承担“核心算法编写”与“项目全局组装”,才是当下提升算力利用率、降低研发成本的最佳路径。
大家在写复杂业务代码时,更倾向于信任哪一个模型的输出?欢迎在评论区分享你的实测经验。
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]