




OpenAI拟租赁俄亥俄州10GW数据中心园区:Nvidia或提供资金支持
2026-06-11
2026-06-13 0
今晚 10 点半,我打开 Kimi Code 官网看一下我的订阅额度准备截图告诉我朋友:天才陨落了。然后发现
订阅额度居然被清空了,又重新充满了。
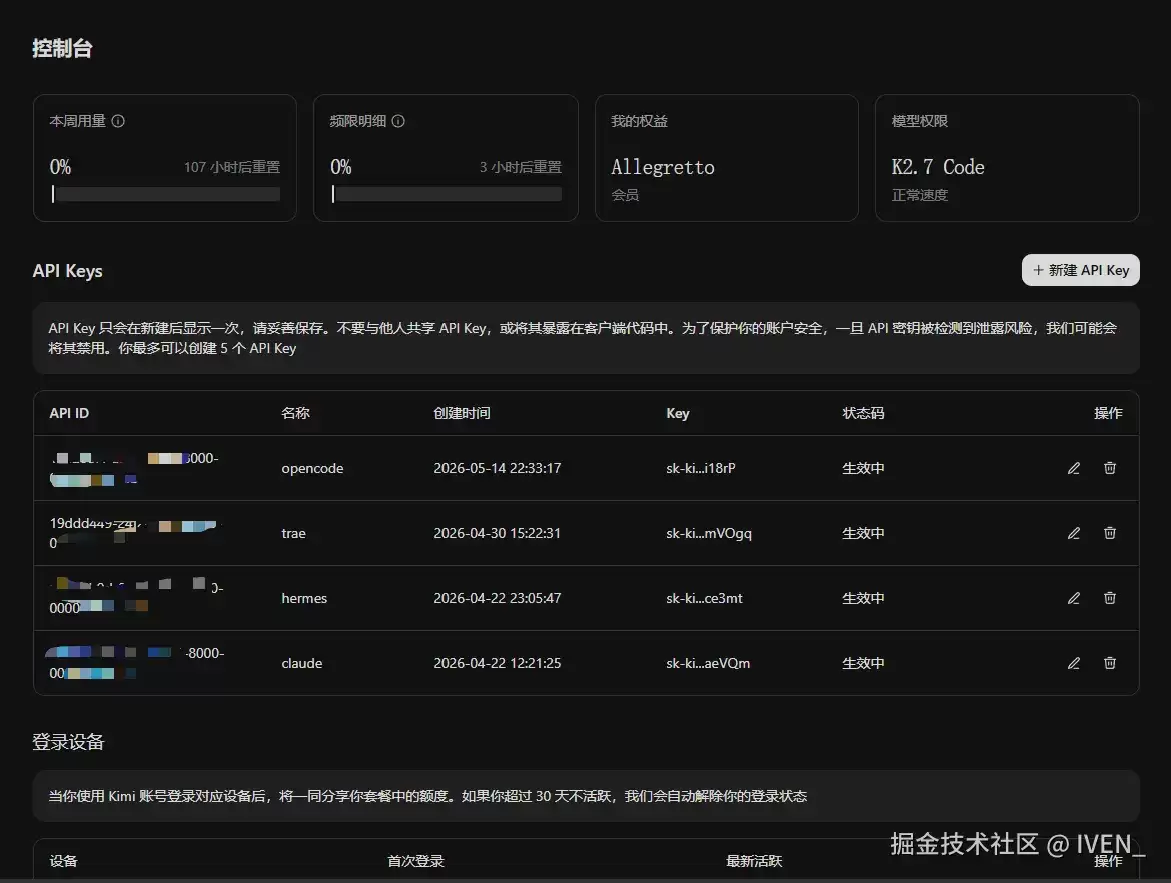
等等,我明明下午就把今天的额度干完了啊
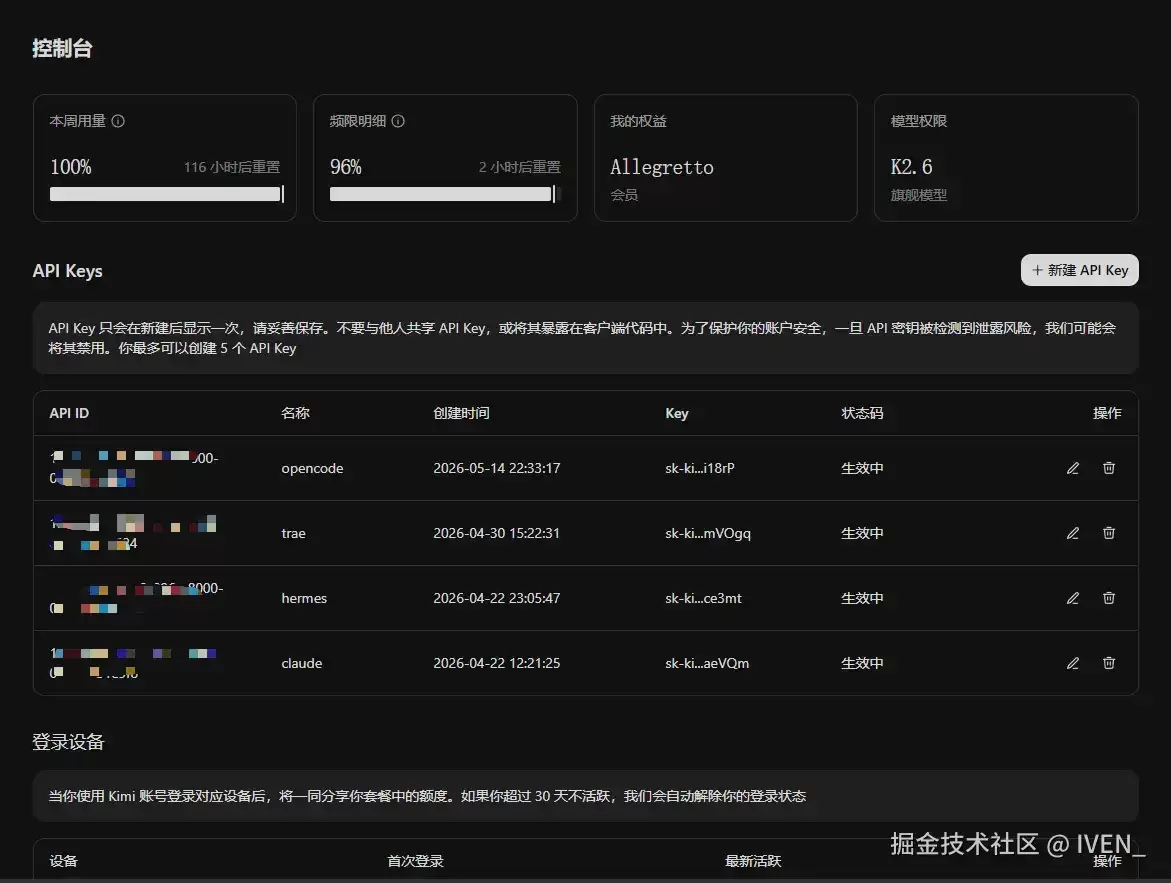
一开始我还以为是 Kimi 的计费系统出 bug 了,突然发现旁边的模型从2.6变成2.7了,我开始查这个模型
Kimi K2.7 Code 今天发布了。
准确说是 2026 年 6 月 12 日下午发布,而我的订阅在晚上 10 点半被重置——大概率是 K2.7 Code 上线后,额度系统也同步刷新了,给所有活跃用户又续了一波。
虽然没看到官方公告说「送额度」,但体验上来说,等于白嫖了半天的 K2.7 Code,也算是发布日的小彩蛋了。
说回模型本身。
2026 年 6 月 12 日,Moonshot AI 正式发布了 Kimi K2.7 Code,权重已开源,API 同步上线。官方宣称这是「迄今为止最强的开源代码模型」。
今年国内 AI 编程模型的赛道肉眼可见地卷起来了——MiniMax M3(2025.12 发布)、DeepSeek V4 Pro(2026.3)、GLM V5.1(2026.4),再到今天的 Kimi K2.7 Code。五家国产模型已经形成了第一梯队,各有所长。
这篇文章纯粹站在国产模型用户的角度,把这五家拉到一起做个横向对比,帮你选模型时有个参考。
| 指标 | MiniMax M3 | DeepSeek V4 Pro | Kimi K2.6 | Kimi K2.7 Code | GLM V5.1 |
|---|---|---|---|---|---|
| SWE-Bench Verified | — | 80.6% | 80.2% | 待公布(推测 82–85%) | — |
| SWE-Bench Pro | 59.0% | 55.4% | 58.6% | 待公布(推测 62–66%) | 58.4% |
| LiveCodeBench v6 | — | 93.5% | 89.6% | 待公布(推测 93–97%) | — |
| Terminal-Bench 2.0 | 66.0% | 67.9% | 66.7% | 待公布(推测 71–75%) | 63.5% |
| HumanEval | — | — | 92% | 待公布 | — |
| 上下文窗口 | 1M | 1M | 256K | 1M | 200K |
| 1M Input 价格 | $0.30 | $0.44 | $0.90 | $0.90 | $0.70 |
| 缓存命中价 | — | $0.0037 | $0.15 | $0.18 | — |
官方公布了以下内部基准的绝对分数,对比 K2.6 的提升:
| 维度 | K2.6 基线 | K2.7 Code | 相对变化 |
|---|---|---|---|
| Kimi Code Bench v2(综合代码能力) | 50.9 | 62.0 | +21.8% |
| Program Bench(程序设计) | 48.3 | 53.6 | +11.0% |
| MLS Bench Lite(长程代码任务) | 26.7 | 35.1 | +31.5% |
| Kimi Claw 24/7 Bench(Agent 自主执行) | 42.9 | 46.9 | +9.3% |
| MCP Atlas(工具调用) | 69.4 | 76.0 | +9.5% |
| MCP Mark Verified(工具调用) | 72.8 | 81.1 | +11.4% |
| Token 消耗 | 100% | 70% | -30% |
MLS Bench Lite 提升 31.5%——上下文窗口拉开的差距 这个基准测的是长程代码任务,比如在一个大型项目中理解代码、做跨文件修改。K2.7 把上下文从 256K 拉到 1M,直接导致这个指标暴涨。如果你经常需要 AI 理解整个项目而不是单文件,这提升是实打实的。
Token 消耗降 30%——变相降价 官方说同样的任务,K2.7 Code 只需要 K2.6 的 70% 的 token。如果属实,0.63 的效果**,甚至比 GLM 还便宜。而且你的订阅额度也能多用 30%,对 Cursor/Cline 这类频繁调用的场景很友好。
Agent 提升 9.3%——虽然低但方向对 Code Bench 涨了 21.8%,但 Agent Bench 只涨了 9.3%。这说明模型变强了,但 Agent 落地还有瓶颈——不是模型一强,Agent 自动就强的。好消息是 MCP 相关的两个基准(Atlas + Mark)都涨了 10% 左右,工具调用的提升是实实在在的,这意味着 Cline、Continue、Hermes Agent 等工具接入 K2.7 后会直接受益。
K2.7 Code 将上下文窗口从 256K 提升到 1M,和 DeepSeek V4 Pro、MiniMax M3 站在了同一起跑线。
对国产模型的用户来说,这很重要:
混用策略(我个人用的方式)
最后聊一下我自己的决策过程。
其实在上周,我本来已经打算下个月把主力模型从 Kimi K2.6 换成 MiniMax M3 了。
原因很简单:M3 有 1M 上下文窗口(K2.6 只有 256K),而且 SWE-Bench Pro 比 K2.6 高(59.0% vs 58.6%),价格还只要 $0.30,只有 Kimi 的三分之一。怎么看都是更好的选择。
但今天 K2.7 Code 一发,情况变了:
所以结论:下个月继续续费 Kimi Code。
当然,这只是基于现有数据的判断。如果一两周后第三方评测出来,发现 K2.7 的 SWE-Bench 没达到预期,那时候再考虑换也不迟。
K2.7 Code 的发布,让我觉得国内编程模型的竞争到了一个很有意思的阶段——基准分的差距在缩小,各家在差异化方向上找到了自己的路。
DeepSeek 走的是 MIT + 最高基准的路线,MiniMax 打性价比和工程修复,Kimi 押注长上下文和工具调用,GLM 深耕国内生态。
说实话,对于做实际项目的开发者来说,SWE-Bench 58% 和 62% 的差距,可能还不如「上下文够不够大」「工具调用好不好用」「返回答不答案」这些日常体验来得重要。
最后分享今晚的小惊喜——如果你也是 Kimi Code 订阅用户,可以打开看看额度是不是也莫名重置了。 如果是,恭喜,白嫖了半天的 K2.7 Code。
发布日期:2026-06-12 本文仅对比国产模型,数据来源:各模型官方技术报告及公开基准榜单
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]