




即墨开展平台业务培训 推进教师管理数字化
2026-06-15
2026-06-18 0
最近做 AI 应用选型时,我发现很多开发者会把 Claude 放在文档分析、代码审查、知识库问答这类场景里优先测试。如果想横向对比 Claude、GPT、Gemini、Claude Code 等模型在同一任务下的表现,也可以把工具整合站点库拉镜像平台 leadhi.cn 作为一个 AI 模型聚合平台入口,先用统一提示词跑样例,再判断哪类模型更适合自己的业务。

所谓“低幻觉”,不是说模型永远不会出错,而是它在信息不足、上下文冲突、问题边界不清时,更倾向于说明限制,而不是直接生成一个看起来很完整的答案。
这点对开发者很重要。因为在真实工程里,模型回答“我不确定”,往往比一本正经地给错结论更有价值。
幻觉到底从哪里来?
大模型本质上是在根据上下文预测下一个 token。它并不是天然连接某个事实数据库,也不会自动知道每个项目的真实业务规则。
所以当问题缺少依据时,模型可能会用语言模式补全答案。
比如你只给它一个 OrderService 文件,它可能推断出订单支付、退款、风控、库存等完整链路。但这些内容在你的项目里未必存在。
这就是工程场景里最常见的幻觉:
不是完全乱说,而是“推断过度”。
Claude 的低幻觉主要靠什么?
从使用体验看,Claude 的低幻觉来自几个方向的共同作用。
第一是指令对齐。
它更容易遵守“只基于上下文回答”“不确定就说明”的要求。
第二是长上下文处理能力。
当输入文档、代码、日志足够完整时,它更倾向于从材料里抽取信息,而不是凭经验补全。
第三是表达风格偏谨慎。
它经常会把“已确认信息”和“可能推测”分开写,这对技术分析很友好。
一个简单对比
下面这个表是我在实际测试中的主观总结,不代表绝对排名,更适合做选型参考:
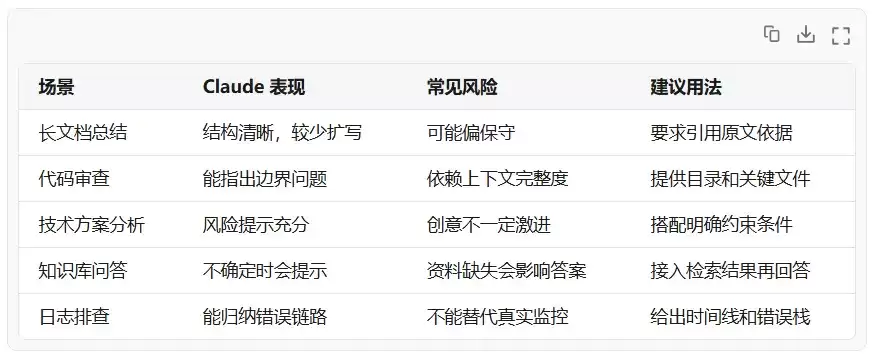
技术逻辑一:让模型学会“不强答”
很多模型的问题不是不会回答,而是太愿意回答。
Claude 的一个特点是,当输入信息不足时,它更容易给出类似这样的表达:
仅从当前内容无法确认原因,需要补充日志、配置或调用链信息。
这类回答看似不够“爽”,但对工程排查很有帮助。
因为真实项目最怕模型把猜测说成事实。
在提示词里,如果明确要求“信息不足请说明缺失项”,Claude 通常能较好执行。
技术逻辑二:更重视上下文证据
低幻觉不只是模型训练问题,也和上下文利用方式有关。
在长文档分析中,Claude 往往会沿着原文结构总结,比如按章节、段落、接口字段、异常日志来组织答案。
这种回答方式降低了“自由发挥”的空间。
举个例子,如果让它分析一份 API 文档,比较稳的要求是:
text
请只基于下面文档回答:
技术逻辑三:把事实和推测拆开
在代码场景里,Claude 比较适合做“基于证据的分析”。
比如你给它一段异常日志,它可能会输出:
已确认:哪个模块抛错
已确认:错误类型是什么
推测:可能与参数为空有关
需要补充:请求样本、配置项、版本信息
这种结构对排障很实用。
它不会直接跳到“最终原因一定是某某配置错误”,而是把路径拆开。
这也是低幻觉模型在工程协作里的优势:它不仅给答案,还能说明答案边界。
实战中如何继续降低幻觉?
不要只依赖模型本身,工作流也很关键。
我建议在技术任务里固定四个要求:
只基于提供材料回答
不确定内容单独列出
结论必须对应依据
关键改动需要人工复核
尤其是代码审查、接口迁移、数据库变更这类任务,不要让模型一次性做完所有决策。更稳的方法是先让它分析,再让它给修改计划,最后逐步执行。
Claude 适合哪些低幻觉场景?
比较适合:
技术文档总结
代码逻辑解释
Pull Request 审查
日志与报错分析
知识库问答草稿
需求文档拆解
不太适合完全无上下文的强事实问答。
如果没有资料输入,再谨慎的模型也只能基于已有训练经验回答,准确性仍然需要验证。
趋势判断:可信输出会比“会生成”更重要
过去大家关注模型能不能写文章、写代码、写方案。现在开发团队更关心的是:模型能不能说明依据,能不能控制边界,能不能减少人工返工。
未来 AI 应用落地的核心,不只是生成能力,而是可验证、可追踪、可集成。
Claude 的低幻觉风格正好契合这个方向。它不是永远正确,但更适合放进需要谨慎判断的工程流程里。
我的结论是:Claude 的价值不在于“回答得最多”,而在于“知道什么时候该少说”。对开发者来说,这种克制反而是一种生产力。
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]