




2026年过半: 具身智能CEO们在聊什么?
2026-06-17
2026-06-18 0
原创 金色传说大聪明 2026-06-17 12:10 北京
744B MoE,40B 激活,1M 上下文,MIT 协议
国产模型的高光时刻
GLM-5.2 现已开源,技术博客同步放出:
744B MoE,40B 激活,1M 上下文,MIT 协议
模型已纳入 GLM Coding Plan,API 同步上线,全量可用,价格跟 5.1 保持一致
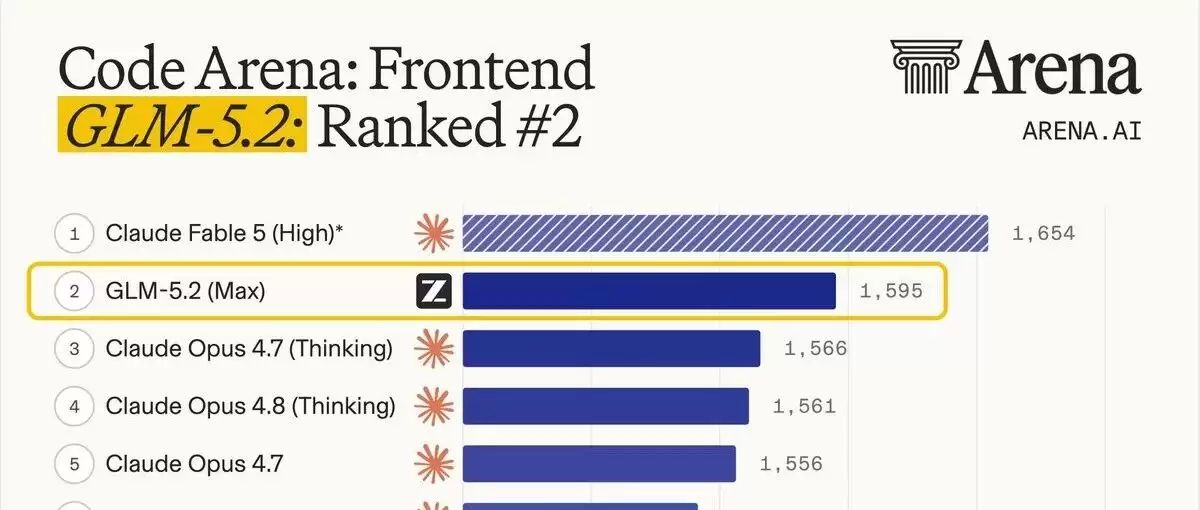
在大家最为关心的 Coding 领域,GLM-5.2 在 Arena 上以 1595 分拿下第二,也是这个Coding 榜单上最强的【可用模型】
考虑到最近 Gemini 不尽如人意,可以说...GLM 挤掉哈基米,荣登 coding 御三家
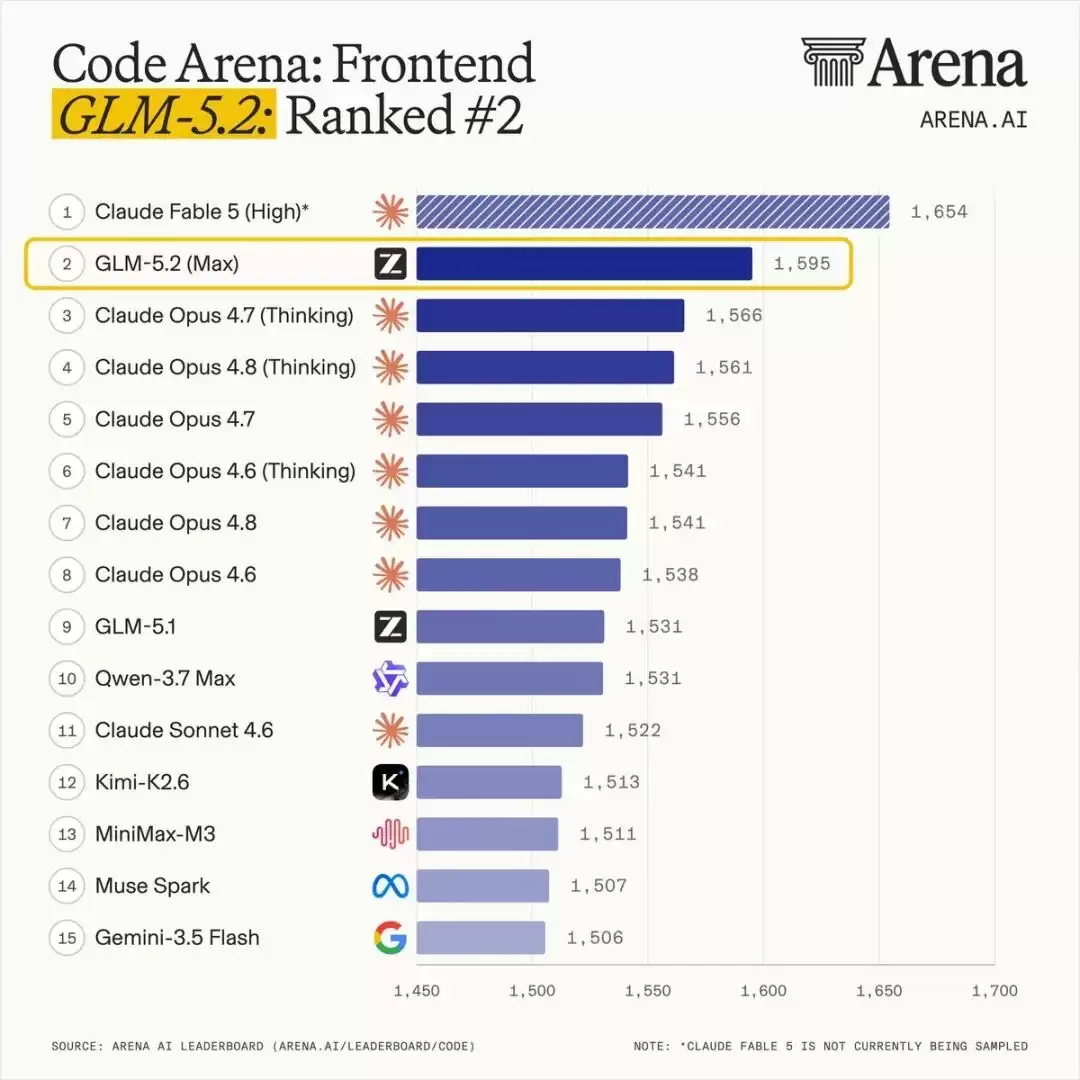
Code Arena: Frontend(来源:arena.ai)
还有就是:今晚在AGI Bar 知识蒸馏有 GLM 开发者见面会,欢迎大家来玩(见文末)
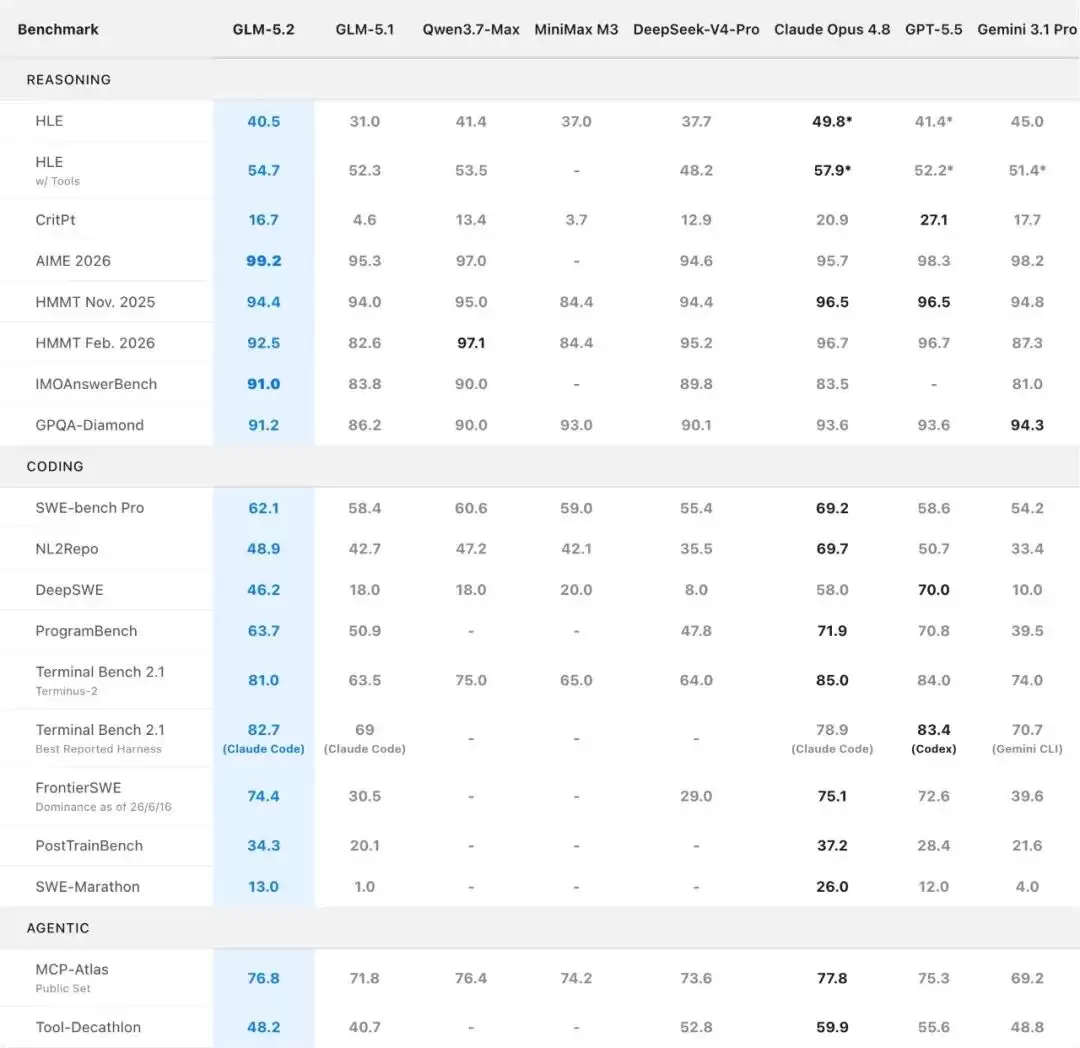
GLM-5.2 Full Benchmark Table
GLM-5.2 专为长程任务能力(Long Horizon Task)而生,全新特色包括:
-Solid 1M 上下文,稳定支撑长程任务
-更强体感更实用的 Coding 能力
-极致 Infra 优化,Day 0 运行在国产算力平台
-MIT 开源协议,允许美国人民使用
三个基准均跑在 1M 上下文、Max 档位、128K 最大输出下,GLM-5.2 在所有开源模型中排名第一
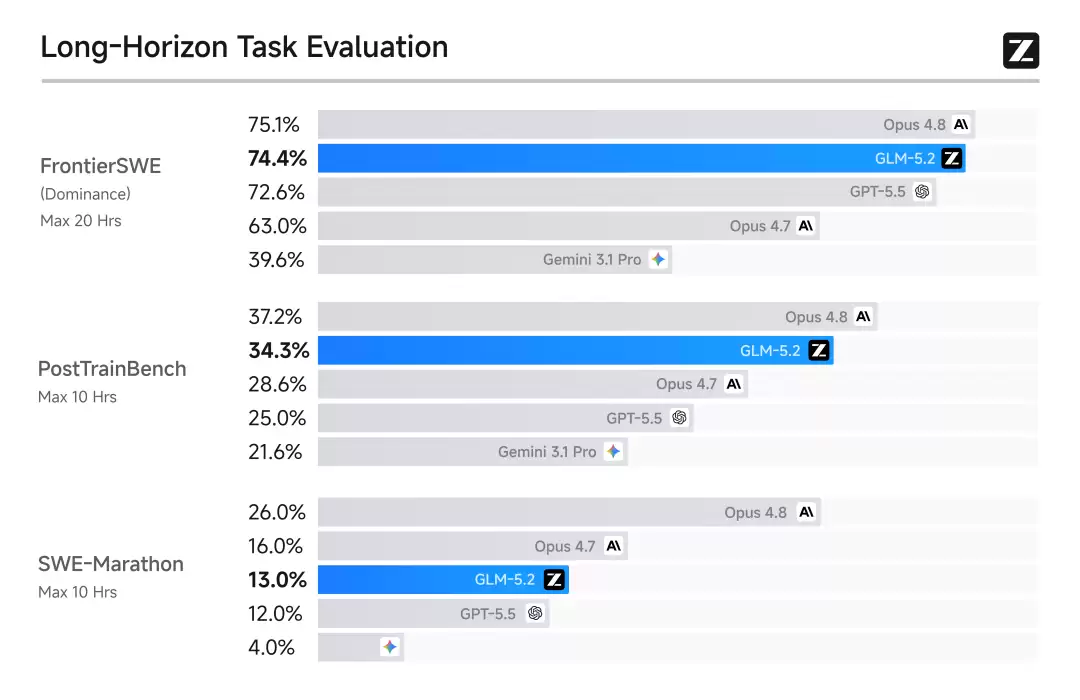
Long-Horizon Task Evaluation
FrontierSWE(20 小时级复杂工程)
Opus 4.8:75.1%,GLM-5.2:74.4%,GPT-5.5:72.6%。差 0.7 个百分点
PostTrainBench(给 Agent 一块 H100,10 小时内做 post-training)
Opus 4.8:37.2%,GLM-5.2:34.3%,GPT-5.5:25.0%
SWE-Marathon(编译器、内核优化等超长周期工程)
Opus 4.8:26.0%,Opus 4.7:16.0%,GLM-5.2:13.0%,GPT-5.5:12.0%。差了一倍,排在 Opus 4.7 后面
8 项 Coding + Agentic 评测中,GLM-5.2 保持开源 SOTA,相比 5.1 跨代提升明显
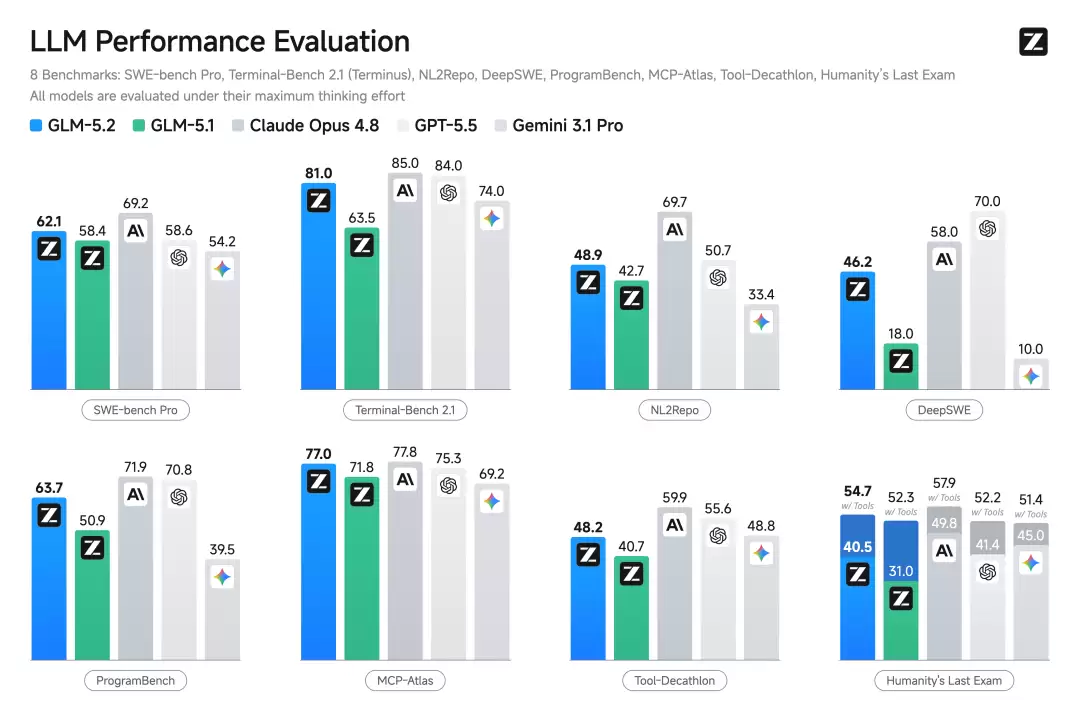
LLM Performance Evaluation
Terminal-Bench 2.1:GLM-5.2 拿 81.0,Opus 4.8 是 85.0,GPT-5.5 是 84.0(5.1 是 63.5)
MCP-Atlas:77.0 vs 77.8。SWE-bench Pro:62.1 vs 69.2。NL2Repo:48.9 vs 69.7,这项差距最大
值得注意的是 HLE with Tools:GLM-5.2 拿了 54.7,Opus 4.8 是 52.3,GPT-5.5 是 52.2
在 Claude Code 上跑 Terminal-Bench 2.1、DeepSWE、SWE-Atlas 的平均分,GLM-5.2 的 High 档跟 Opus 4.8 的 High 基本重合(约 73%),Max 档 GLM-5.2 约 75%,Opus 4.8 约 78%
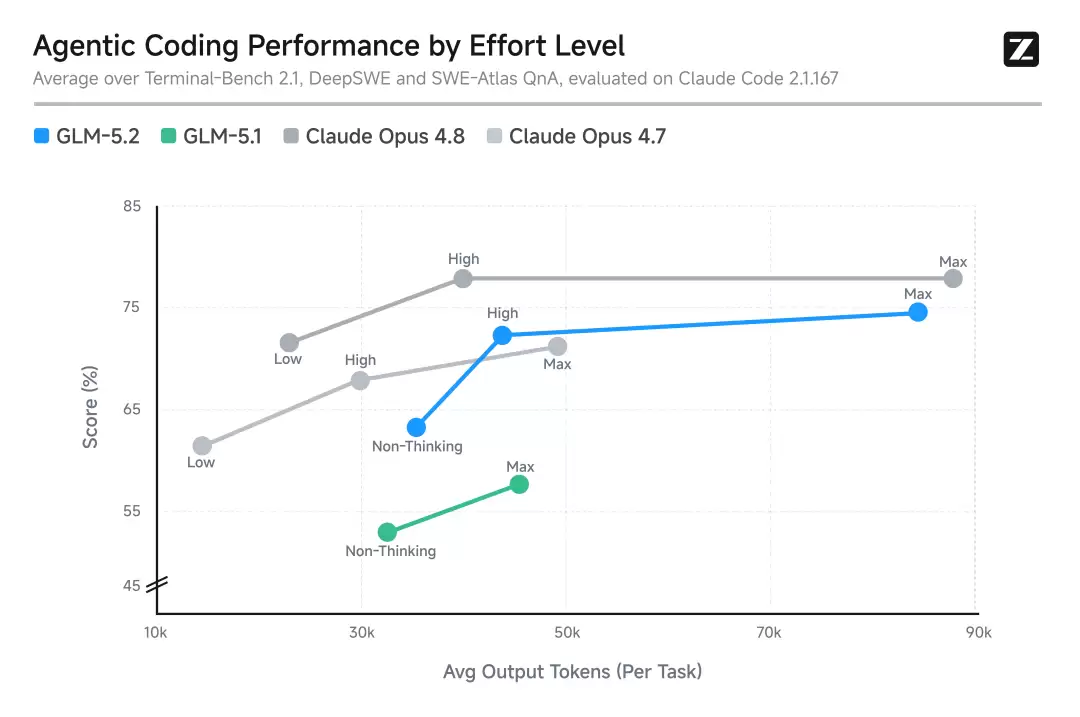
Agentic Coding Performance by Effort Level
对比 GLM-5.1:Non-Thinking 到 Max 全程低 15 到 20 个百分点,代际提升很大
为了让 1M 上下文在工程上真正可用,GLM-5.2 在架构和推理引擎上做了系统优化
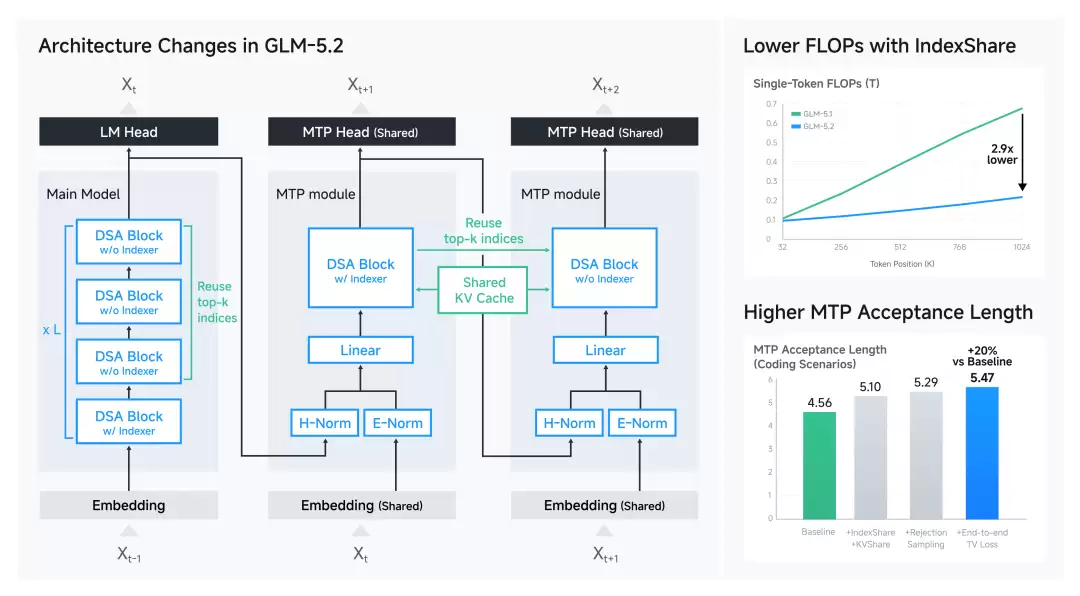
GLM-5.2 Architecture for 1M Context
每 4 层 transformer 共享一个轻量 indexer,top-k 索引复用到后续 3 层,省掉 3/4 的 indexer 点积和 top-k 计算。从 mid-training 阶段就用 IndexShare 训练
改进 MTP 层用于投机解码:indexer 只在第一步放置,后续步骤复用 top-k 索引。这样第二步的 KV cache 只包含来自 target model 的隐状态,消除了 GLM-5.1 中的训练和推理不一致
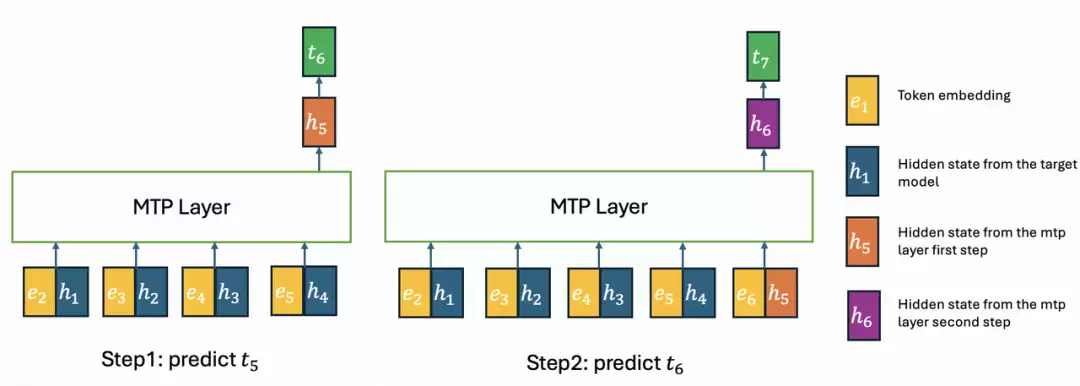
MTP Inference with IndexShare
四步叠加效果:baseline 4.56 > +IndexShare+KVShare 5.10 > +Rejection Sampling 5.29 > +End-to-end TV Loss 5.47(+20%)
上下文从 200K 扩到 1M 后,推理瓶颈转向 KV-cache 容量、长上下文 kernel 开销和 CPU 侧开销。三个方向优化:基于 LayerSplit 的细粒度内存管理和并行策略,长上下文 kernel 与 cache 传输 pipeline 协同,CPU 侧缓存管理和请求调度
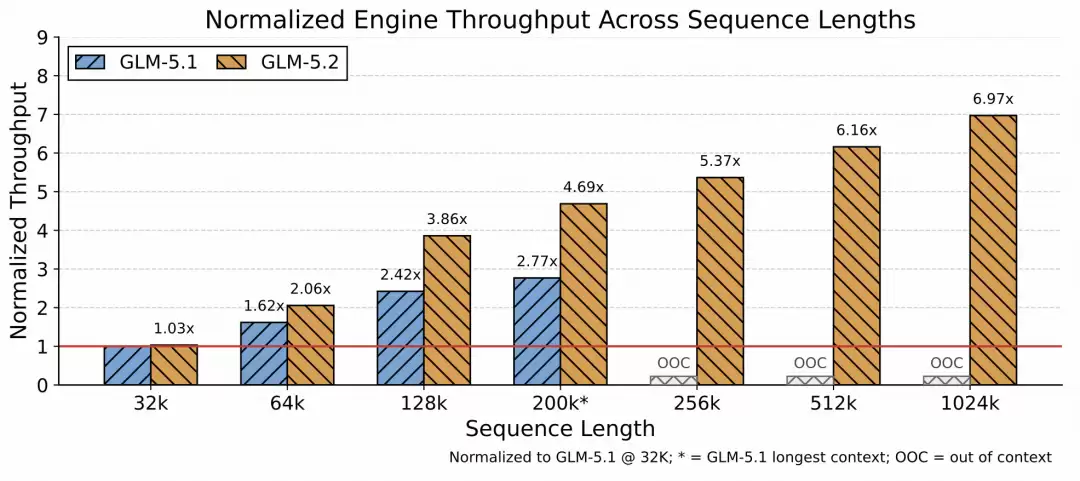
随上下文长度增长,GLM-5.2 的吞吐优势更大
GLM-5.2 的 agentic RL post-training 涉及更大规模、更多领域、更复杂的执行模式。长程交互、工具调用、子任务拆解、多轮环境反馈都对 rollout 和训练编排提出了更高要求。两个核心改动:一是用 slime 框架统一训练和大规模推理 rollout,二是针对 coding RL 的 reward hacking 问题引入 anti-hack 模块
slime 是从训练到大规模推理 rollout 的一体化基础设施,支持 white-box / black-box rollout、compact trajectory、sub-agent workflow。GLM-5.2 的 post-training 用 slime 做并行 OPD 训练,将 10+ 个专家模型合并为最终模型,整个 OPD 过程约两天完成
长程任务的执行轨迹更长,经过 compaction 后子轨迹数量和长度差异很大。GLM-5.2 从 group-wise 优化转向基于 critic 的 PPO,用 token-level advantage 适配不等长子轨迹
Coding RL 容易 reward hacking:读取受保护评测文件、从上游 commit 复制答案、直接 curl 拉取目标代码。GLM-5.2 引入 anti-hack 模块,两阶段检测(rule-based filter + LLM judge),在线拦截 hack 行为并返回 dummy 信息,让 rollout 继续而非中断
模型权重遵循 MIT License,GitHub / Hugging Face / ModelScope 均已上线,vLLM、SGLang、transformers 等主流推理框架已支持
-BigModel 开放平台:docs.bigmodel.cn/cn/guide/models/text/glm-5.2
-Z.ai:docs.z.ai/guides/llm/glm-5.2
-技术博客:z.ai/blog/glm-5.2
今晚 7 点,z.ai 团队讲来到 AGI Bar(上海),带一场「开发者面对面」活动。你能看到 5.1 和 5.2 的对比测试,还能听 Builder 们激情开麦
无需预约,直接 walk-in

Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]