




2026年过半: 具身智能CEO们在聊什么?
2026-06-17
2026-06-18 0
三个臭皮匠顶个诸葛亮...

过去几年,大模型行业的主叙事一直很简单:谁拥有最强的基础模型(参数更大、上下文更长、推理更深,工具调用更稳),谁就拥有下一阶段 AI 应用的入口。最近发生的事还证明(Claude Fable 禁令前,大家做了什么?):模型越强,死得越快...
但 OpenRouter Fusion 的出现,为我们提供了一个新视角(理论其实并不新鲜):如何把多个不完美的模型、工具、路由器、judge、搜索系统和数据治理策略组织起来,构成一个比任何单一模型都更可靠的复合智能系统?
所以 OpenRouter Fusion 不是一个新的基础模型。它更准确的定义是:一种被产品化的多模型合议 API 原语。
它不是把一次请求路由给某个单一模型,而是把同一个问题并行发送给一个模型面板,让多个模型独立分析,再由 judge 模型产出结构化审议结果,最后由外层模型或 judge 基于这份结构化分析生成最终答案。OpenRouter 官方文档[1]明确写到,Fusion 会让 panel models 并行回答,然后由 judge 比较它们的回答,输出 consensus、contradictions、coverage gaps、unique insights、blind spots 等结构化信息,外层模型再基于这些分析写出更好的最终回答。
这件事的意义不只是“多调几个模型”。它标志着LLM 应用架构从单模型调用进入复合推理编排阶段。
OpenRouter Fusion 的核心价值不是“更便宜地调用最强模型”,而是“用额外的推理时计算(inference-time compute)换取更高质量、更高覆盖率和更强分歧诊断能力”。
它适合高价值、低频、容错成本高的任务,例如深度研究、技术方案比较、合规分析、架构决策、战略研判和高风险总结;不适合默认用于简单问答、实时聊天、大规模低毛利调用或严格确定性的代码拼接。
如果说过去 AI 产品竞争的是“接入了哪个模型”,那么 Fusion 代表的下一阶段竞争点是:谁更会组织模型。
OpenRouter 原本就是一个模型网关。它可以在多个 provider 之间做请求路由、fallback、价格排序、延迟排序、吞吐排序、ZDR 过滤和数据策略控制。官方 provider routing 文档显示,OpenRouter 默认会把请求路由到当前最合适的 provider,并支持order、allow_fallbacks、data_collection、zdr、only、ignore、sort等 provider 级控制项。
但 Fusion 不是传统意义上的 provider routing。传统路由解决的是:
这个请求应该发给哪个模型 / 哪个供应商?
Fusion 解决的是:
这个问题是否值得让多个模型共同审议?
如果值得,哪些模型应该参与?
它们的共识、分歧、盲点分别是什么?
最终答案应该如何吸收这些结构化信息?
所以,Fusion 更像是 OpenRouter 路由层之上的一个认知升级层,也可以叫 deliberation layer。它不是替代 provider routing,而是把 provider routing、server tools、web search、web fetch、judge 和模型面板组合成一次服务端多模型合议。
OpenRouter 官方文档给出了 Fusion 的三种开发者入口:openrouter/fusion模型别名、openrouter:fusionserver tool、以及 fusion plugin;plugin 文档明确说三者命中同一条 pipeline。广义上,OpenRouter 还提供Chatroom[2]入口用于无代码体验,因此从产品形态上可以说有四种使用方式:Chatroom、model slug、server tool、plugin。
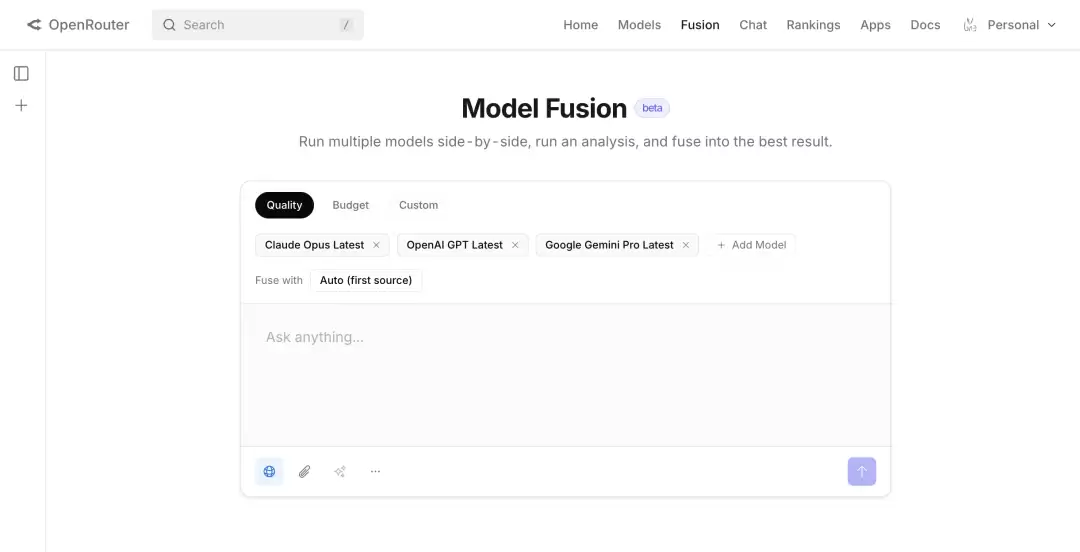
这也是 Fusion 工程化程度较高的地方:它不是让开发者自己在客户端串联多个 API,然后手写 prompt 去 merge;而是把多模型合议封装成了一个服务端原语。
Fusion 的工作流可以抽象为下面这条链路:
用户问题
↓
外层模型判断是否需要 Fusion
↓
多个分析模型并行作答
↓
judge 模型比较所有回答
↓
输出结构化审议报告
↓
外层模型基于审议报告生成最终答案
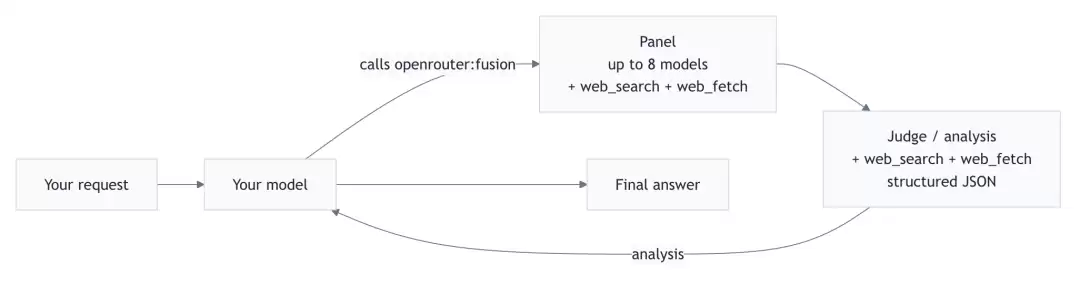
OpenRouter 官方文档描述得很清楚:当使用model: "openrouter/fusion"时,router 会把别名解析为真实模型,并注入openrouter:fusion工具;模型会判断任务是否值得 deliberation,如果值得就调用 Fusion;随后 panel models 会并行回答同一个 prompt,并且 panel 与 judge 都默认启用openrouter:web_search和openrouter:web_fetch。
这里有三个关键点:
第一,Fusion 是按需触发,不是每个请求都默认进入重型合议模式。官方文档写明,模型会自己判断是否调用openrouter:fusion;如果开发者想强制每次都调用,可以设置tool_choice: "required"。
第二,judge 的职责是比较,不是简单合并。官方 server tool 文档明确说,judge 比较 panel responses,而不是把它们 merge;它会把多数模型都同意的内容视为较高置信度共识,同时暴露 contradictions、unique insights 和 blind spots。
第三,Fusion 有工程级容错。server tool 文档显示,如果部分 panel models 失败,只要至少一个成功,工具仍然返回status: "ok",并附带failed_models;如果 panel 成功但 judge 失败,系统不会直接报错,而是返回原始 panel responses,让外层模型仍然可以生成答案。只有当所有 panel 都无法产生有用输出时,才会返回status: "error"。
这说明 Fusion 的定位不是“完美的模型裁判”,而是一个面向真实 API 环境设计的服务端推理管线。它承认模型会失败、judge 会失败、provider 会失败,所以必须有 degradation path。
OpenRouter 在 2026 年 6 月 12 日发布了官方 benchmark 文章Surpassing Frontier Performance with Fusion[3],使用 Perplexity 的 DRACO 深度研究基准测试了 100 个复杂研究任务。官方给出的核心结论是:多个 Fusion panel 在 DRACO 上持续优于单模型;其中 Fable 5 + GPT-5.5,经 Opus 4.8 融合后达到 69.0%,高于文中列出的所有单模型结果。
官方文章中的关键分数如下:
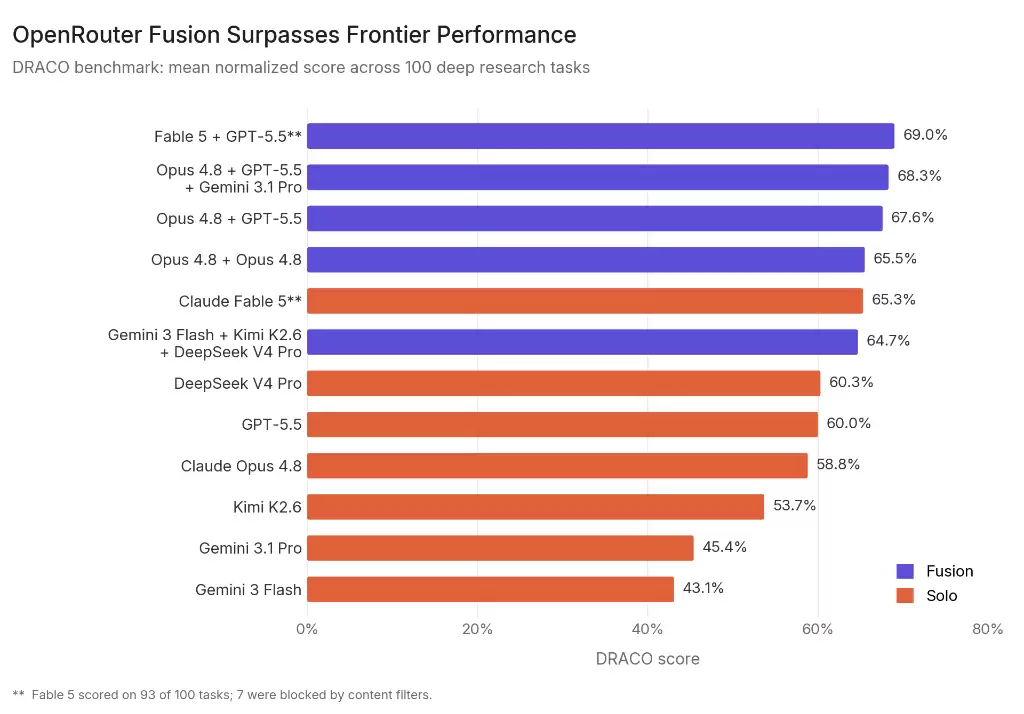
这组数据很重要,但不能被简单读成 “Fusion 全面碾压单模型”。更准确的解读应该分三层:
第一,前沿模型面板确实给出了 beyond-frontier 的结果。Fable 5 + GPT-5.5 由 Opus 4.8 融合后的 69.0%,超过了 Fable 5 单独的 65.3%,也超过了 GPT-5.5 单独的 60.0% 和 Opus 4.8 单独的 58.8%。这支持了一个判断:在深度研究类开放任务中,多模型的异构认知路径确实可能产生超过单模型的系统能力。
第二,自我融合也有显著收益。OpenRouter 文章中特别提到,Opus 4.8 + Opus 4.8 的 self-fusion 得到 65.5%,比 Opus 4.8 solo 的 58.8% 高 6.7 个百分点。官方对此的解释是,收益不完全来自不同模型架构的多样性,也来自 synthesis 本身:同一个模型两次运行可能产生不同推理路径、不同工具调用和不同来源选择。
第三,预算面板的商业意义可能比最高分更大。Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro 的 budget panel 达到 64.7%,接近 Fable 5 的 65.3%,同时官方声称成本约为 Fable 5 的一半。这个结果真正刺激市场的地方不是“最高分”,而是它暗示:通过合理的多模型合议,中低成本模型组合可能逼近前沿单模型的深度研究能力。
注意,这里需要冷静一下:官方文章也说明,Fable 5 相关结果中有 7 个 DRACO 任务因为内容过滤没有完成,因此 Fable 结果基于 93 个 scored tasks,而不是完整 100 个任务;这使得与完成全部 100 个任务的模型相比存在轻微不均衡。
所以,这组分数最稳妥的结论不是 “Fusion 已经替代最强单模型”,而是:在 DRACO 这类英文、文本型、深度研究任务上,Fusion 显示出显著的测试时计算收益;但这些收益能否稳定迁移到生产任务、长时程 agent、代码执行、多模态任务和非英语场景,还需要进一步验证。
Fusion 不是为简单事实问答设计的。它擅长的问题通常是开放式、跨领域、需要检索、需要权衡、需要引用和需要多角度判断的问题。因此,用传统选择题 benchmark 评估 Fusion,很容易低估或误判它的价值。
DRACO[4]的全称是 Deep Research Accuracy, Completeness, and Objectivity。Perplexity 的论文介绍说,DRACO 包含 100 个复杂 deep research tasks,横跨 10 个领域,并要求从 40 个国家的信息源中获取材料;任务来自 Perplexity Deep Research 的真实使用模式,并经过匿名化、筛选和增强。
DRACO 的评分方式也更适合研究类任务。论文写到,输出会按照 task-specific rubrics 在四个维度上评分:事实准确性、分析广度与深度、呈现质量、引用质量。每个任务平均包含 39.3 条评分标准,其中约一半针对事实准确性,另有标准评估分析深度、表达清晰度和 primary source citation。DRACO 还包含负向评分标准,例如危险医疗建议会被严重惩罚。
这与 Fusion 的目标高度匹配。Fusion 不是为了让模型“说得更像专家”,而是试图让系统在复杂研究任务中减少遗漏、暴露矛盾、提高来源覆盖,并把不同模型的独特发现沉淀成结构化中间产物。
但 OpenRouter 自己也提醒了 DRACO 的局限。官方 benchmark 文章写到,DRACO 是 text-only、English-only、static task set;绝对分数会受到 judge model choice 影响,DRACO 论文中不同 judge 会带来 10–25 分的绝对分数变化,因此更适合观察相对排序,而不是把单次绝对分数当成普适真理。
还有一个很现实的问题:评测污染。
OpenRouter 文章说,当 panel models 启用 web search 后,它们会在搜索过程中找到 DRACO grading rubric。虽然这并非模型有意作弊,但确实暴露了 benchmark contamination 风险。OpenRouter 的处理方式是通过 web_search 的excluded_domains和 web_fetch 的blocked_domains阻止模型访问相关 benchmark rubric 页面。
这点非常关键。Fusion 这类联网多模型系统的评估,比普通单模型评估更容易受到搜索污染、提示注入、来源重复和 judge 偏差影响。未来评估复合 AI,不能只看“分数”,还要看:
是否隔离 benchmark rubric
是否统一工具预算
是否统一搜索权限
是否记录 panel responses
是否记录 judge analysis
是否控制 judge drift
是否评估成本 / 延迟 / 质量三者关系
Fusion 的能力提升来自 test-time compute,也就是推理阶段追加计算。
它的成本模型大致是:
Fusion Cost
≈ 外层模型调用
+ N 个 panel 模型调用
+ 1 个 judge 模型调用
+ web_search / web_fetch 工具成本
+ 额外 reasoning tokens
OpenRouter 文档明确写到,Fusion 会运行 N 个 panel calls + 1 个 judge call,并叠加正常请求;默认 3 模型 panel 大约是同 prompt 单次 completion 成本的 4–5 倍,成本随 panel size 线性增长。
延迟同样不可忽略。虽然 panel 是并行执行,不会按模型数线性相加,但最终延迟仍然大致由最慢的 panel、judge 分析时间、外层生成时间和工具调用延迟共同决定。OpenRouter 官方 FAQ 写到,Fusion 被调用时通常会比标准调用慢 2–3 倍。
所以 Fusion 不应该被默认加到每个请求上。
它更适合被视为一种“高价值推理档位”:
普通请求:单模型直接回答
中等复杂请求:更强单模型 / advisor
高复杂请求:低成本 Fusion panel
高价值高风险请求:前沿 Fusion panel + 多 judge + 工具验证 + 人工审核
未来 AI 产品很可能会把“思考深度”做成显式产品层级:快速回答、标准回答、深度分析、审议模式、可审计研究报告。Fusion 代表的是其中的“审议模式”。
Fusion 的思想并不是凭空出现的。它背后有清晰的学术脉络:Mixture-of-Agents[5],也就是 MoA。
Together AI 等研究者在 2024 年提出的 MoA 论文中,把多个 LLM agent 组织成分层结构。每一层有多个 agent,后续层会读取前一层 agent 的输出作为辅助信息再生成回答。论文报告称,MoA 在 AlpacaEval 2.0、MT-Bench 和 FLASK 上达到很强表现,其开源模型组合在 AlpacaEval 2.0 上取得 65.1%,高于文中对 GPT-4 Omni 的 57.5% 对比成绩。
Fusion 可以被看作 MoA 思想的产品化版本,但它比学术 MoA 更克制。很多 MoA 研究会探索多层堆叠、多轮交互、agent 之间相互 critique;Fusion 则将流程约束在服务端单层递归保护内。OpenRouter 文档写明,内部 Fusion 调用会携带x-openrouter-fusion-depthheader,panel 和 judge 不能递归调用openrouter:fusion,plugin 会拒绝二次注入工具,从而把 deliberation 限制在单层。
这种克制非常重要。学术系统可以追求上限,产品系统必须控制边界。递归不受控的 agent 系统,最容易出现成本爆炸、延迟爆炸和不可观测故障。
从研究趋势看,Fusion 后续可能会吸收几条 MoA 分支的思想。
SMoA,也就是Sparse Mixture-of-Agents[6],提出 Response Selection 和 Early Stopping,用稀疏信息流减少 dense multi-agent 架构中的冗余交互,同时通过不同 role descriptions 提高 agent 多样性。论文称 SMoA 能在接近传统 MoA 表现的情况下显著降低计算成本。
Self-MoA[7]则给 Fusion 提供了一个反向提醒。Rethinking Mixture-of-Agents[8]一文发现,在很多场景下,对同一个强模型进行多次采样再聚合,可能超过混合多个不同模型的标准 MoA;论文指出 MoA 对候选输出质量非常敏感,引入较弱模型可能拉低平均质量。
Pyramid MoA[9]则代表更接近生产系统的方向:动态升级。它用轻量 router 根据小模型之间的语义一致性和置信度判断问题是否困难,只有必要时才升级到更贵的模型层;论文报告称该系统在 GSM8K 上接近 oracle baseline,同时降低了计算成本。
这些研究共同指向一个判断:下一代 Fusion 不会是“固定面板每次全调用”,而会是“基于任务价值、分歧程度、置信度和预算的动态推理调度”。
Fusion 的关键中间层是 judge。没有 judge,多模型系统就只是多个答案的堆叠;有了 judge,系统才能把多个回答转化为结构化审议结果。
但 judge 本身也是 LLM。
这带来一个根本问题:裁判也会有偏见。
LLM-as-a-Judge[10]研究已经指出,LLM judge 的可靠性需要严肃设计,包括一致性、偏差缓解、适用场景和标准化流程。相关综述把这些问题视为构建可靠 LLM judge 的核心挑战。
位置偏差是一个典型问题。Judging the Judges 一文系统研究了 pairwise comparison 中的 position bias,发现 capable LLM judges 的位置偏差并非随机噪声,而会随 judge、任务和候选答案质量差异发生变化。
自偏好也是一个问题。Self-Preference Bias in LLM-as-a-Judge 一文指出,LLM 可能偏好更熟悉、更低困惑度的文本,而不一定更接近人类判断;这种偏差可能导致 judge 更喜欢某类风格或某个模型家族的输出。
所以,Fusion 的 judge 不能被神化为“真理裁判”。它应该被看成一个结构化评审器,而且必须被约束。
生产级 Fusion 系统至少应该做这些事:
1. 明确 judge rubric,避免自由发挥
2. 将事实准确性、分析深度、表达质量、引用质量拆开评分
3. 随机化 panel response 顺序,缓解 position bias
4. 对关键事实调用外部验证工具,而不是只靠 judge 文本判断
5. 记录 panel responses、judge analysis、最终答案,方便审计
6. 对 judge 做回归测试,监控 judge drift
7. 高风险领域引入人工审核
未来 judge 也不一定是一个通用模型。更可能出现的是 judge stack:
factuality judge
citation judge
security judge
legal risk judge
medical safety judge
code execution judge
business reasoning judge
human reviewer
也就是说,Fusion 的最终形态可能不是“一个 judge 总结多个模型”,而是“多个验证器审计一次复杂推理”。
Fusion 的另一个硬核问题是数据治理。
单模型调用中,同一个 prompt 通常只会发送给一个模型供应商。Fusion 则可能把同一个 prompt 发送给多个 panel 模型、一个 judge 模型,以及 web_search / web_fetch 后端。OpenRouter 文档写明,panel 和 judge 都启用openrouter:web_search与openrouter:web_fetch,以便模型在回答和分析时拉取新鲜来源。
这对研究任务很有用,但也意味着敏感问题的数据暴露面扩大了。
OpenRouter 提供了一些治理控制。例如 ZDR 文档显示,Zero Data Retention 意味着 provider 不会存储数据;OpenRouter 支持全局、按模型组、按 guardrail、按请求强制 ZDR。Provider routing 文档也显示,开发者可以通过data_collection: "deny"控制是否使用可能存储数据的 provider,并可以通过zdr: true将请求限制到不保留 prompts 的端点。
但从系统设计角度看,Fusion 的数据最小化天然比单模型调用更难。
高敏场景下,开发者不应该简单地“开启 Fusion 就完事”,而应该明确:
哪些模型可以参与 panel
哪些 provider 可以被路由
是否要求 ZDR
是否允许 web_search / web_fetch
搜索工具是否有域名白名单 / 黑名单
是否允许跨境处理
是否记录 prompt
是否需要脱敏
是否需要人工审批
Fusion 把智能能力做强的同时,也把治理问题做复杂了。
Fusion 的强项是开放式、跨领域、多源、需要比较和权衡的任务。
典型适用场景包括:
深度研究报告
技术路线比较
架构决策评审
法规 / 合规初步分析
投资尽调
竞品分析
安全审计
政策影响分析
高风险摘要
专家观点对照
这些任务有一个共同点:答案不是简单的对错,而是需要覆盖多个角度、识别证据强弱、暴露分歧、发现盲点。
Fusion 不适合默认用于:
简单事实问答
短文本改写
普通翻译
低价值闲聊
高频客服
严格实时交互
确定性代码拼接
批量低毛利 API 调用
尤其是代码生成,要谨慎。
Fusion 不应该被理解为“多个模型一起写代码,然后融合成最佳代码”。复杂代码的正确性具有强耦合特征:变量作用域、依赖版本、接口契约、错误处理、测试假设和运行环境必须保持一致。把多个模型的实现方案混在一起,很容易生成“看起来合理但跑不起来”的代码。
更合理的模式是:
主模型负责编码
Fusion 负责架构评审、风险发现、边界条件检查、替代方案比较
测试工具负责验证
人类 reviewer 负责最终判断
OpenRouter 自己在 FAQ 中也明确说,Fusion 不是 coding models 的 drop-in replacement,更适合让 coding model 在架构决策或 best practice research 等值得花更多时间和成本的问题上选择性调用 Fusion。
Fusion 最值得关注的产品思想,不是“多个模型更聪明”,而是它把分歧变成了系统的一级输出。
传统 AI 产品会隐藏不确定性。用户提问,模型输出一个平滑答案。即使内部有多个可能解释,最终也会被压缩成一个确定叙述。
Fusion 反过来:它把不确定性结构化。
consensus:多数模型都同意什么
contradictions:模型在哪些问题上冲突
partial_coverage:哪些点只有部分模型覆盖
unique_insights:哪个模型提出了独特洞见
blind_spots:所有模型都遗漏了什么
这会改变专业 AI 产品的交互形态。
未来高价值 AI 产品的答案,可能不再只是:
这是最终结论。
而是:
这是最终结论。
这是高置信共识。
这是主要分歧。
这是少数派洞见。
这是证据不足之处。
这是需要人类补充上下文或做价值判断的地方。
在法律、医学、金融、战略、科研、政策等领域,这种分歧诊断比“生成一篇流畅长文”更有价值。
因为真实世界的复杂问题,往往不是没有答案,而是有多个局部正确、彼此冲突、依赖前提的答案。Fusion 的价值不是消灭分歧,而是把分歧转化为可操作的信息。
OpenRouter Fusion 目前还不是终局。它更像是一个强烈信号:模型网关正在从 traffic layer 演化为 reasoning layer。
未来 1–3 年,复合智能栈大概率会沿着五个方向演进。
今天的 Fusion 可以配置 panel,但仍然偏显式配置。未来系统会根据任务类型、风险等级、预算、模型历史表现和实时分歧程度,动态选择 panel。
Self-MoA 研究提醒我们,异构模型不是越多越好。弱模型会带来噪声,judge 也可能被低质量但流畅的答案误导。未来的关键不是堆模型数量,而是优化模型组合的互补性。
最好的 panel 不是最贵模型列表,而是错误模式互补的认知组合。
每个严肃 AI 产品都会拥有自己的 judge stack,就像软件工程中的测试体系。
没有 judge 的 agent,就像没有测试的代码。没有日志和审计的 Fusion,就像不可复现的实验。
用户会为不同的“思考深度”付费。快速回答便宜,深度审议更贵,可审计报告最贵。AI 产品的商业模式会从“按 token 计费”逐渐转向“按认知质量与风险等级计费”。
当模型能力越来越强,模型访问权、数据驻留、ZDR、provider policy、区域路由和供应商冗余会变得越来越重要。OpenRouter sovereign AI 文档也把 AI workloads 和处理数据留在特定地理与司法边界内,作为企业与政府越来越关注的能力。
复合 AI 不只是性能架构,也会成为供应链架构。
OpenRouter Fusion 的重要性,不在于它是不是某个 benchmark 的第一名。
它真正重要的地方在于:它把多模型合议做成了开发者可以直接调用的 API 原语。
这意味着 AI 应用正在从:调用一个模型。
走向:组织多个模型、工具、judge 和治理策略。
过去的核心问题是:哪个模型最强?
未来的核心问题会变成:
Fusion 当前形态还有很多问题:成本高、延迟高、judge 有偏、隐私暴露面扩大、DRACO 结果不一定泛化到所有生产任务。
但它指向的方向非常明确:AI 的能力边界,正在从单个模型的参数规模,迁移到复合智能系统的组织能力。
未来真正的护城河,不只是拥有最强模型,而是拥有最强的智能编排栈:动态路由、分歧诊断、结构化 judge、工具验证、成本优化、数据治理和可审计推理。
换句话说,下一阶段 AI 竞争,不只是模型能力的竞争,而是智能系统工程能力的竞争。
[1]
OpenRouter 官方文档:https://openrouter.ai/docs/guides/routing/routers/fusion-router
[2]Chatroom:https://openrouter.ai/fusion
[3]Surpassing Frontier Performance with Fusion:https://openrouter.ai/blog/announcements/fusion-beats-frontier
[4]DRACO:https://arxiv.org/abs/2602.11685
[5]Mixture-of-Agents:https://arxiv.org/abs/2406.04692
[6]Sparse Mixture-of-Agents:https://arxiv.org/abs/2411.03284
[7]Self-MoA:https://arxiv.org/abs/2502.00674
[8]Rethinking Mixture-of-Agents:https://openreview.net/forum?id=ioprnwVrDH
[9]Pyramid MoA:https://arxiv.org/abs/2602.19509
[10]LLM-as-a-Judge:https://arxiv.org/abs/2411.15594
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]