




2026年过半: 具身智能CEO们在聊什么?
2026-06-17
2026-06-19 0
魔搭ModelScope社区 2026-06-18 15:22 美国

腾讯联合开源具身智能模型HyVLA-0.5。该模型基于超万小时自研UMI数据训练,在仿真基准中成功率超90%,真机任务接近100%。其创新的强化学习方法有效利用失败数据优化策略,此次开源旨在推动机器人操作系统的实际部署与行业共研。
腾讯 Robotics X、福田实验室与混元团队联合发布面向真实世界机器人操作任务的端到端具身智能模型Hy-Embodied-0.5-VLA(简称HyVLA-0.5)。HyVLA-0.5 基于自研的亚毫米级高精度指套式 UMI 数据采集软硬件(专利:2025020117CN),构建了超过 10000 小时的人类示教数据,使模型在监督训练阶段无需任何遥操作数据,也能在多本体真机任务中取得高部署成功率;基于纯自研 UMI 数据训练的模型,HyVLA-0.5 在 RoboTwin 2.0 仿真基准的简单与复杂设置下均超过 90%,是目前该榜单上 SOTA 的开源 VLA 模型。
在此基础上,HyVLA-0.5 首次将 Proximalized Preference Optimization(PRO)系统性引入基于流匹配的 VLA 强化后训练,充分利用真实机器人失败数据,实现真实机器人任务接近 100% 的成功率。
HyVLA-0.5 开源了两个检查点:
Hy-VLA-UMI是预训练检查点,基于 10000 多小时高保真 UMI 示教数据训练,可作为面向目标机器人平台下游微调的通用起点;
Hy-VLA-RoboTwin是在 RoboTwin 2.0 全部 50 个双手操作任务上微调后的 SFT 检查点,平均成功率达 90.9%(Clean)/ 90.1%(Randomized),在已发表的 VLA 方法中处于领先水平。两者均构建于 Hy-Embodied-0.5 MoT 主干之上。
开源地址:
Hy-Embodied-0.5-VLA-UMI:https://modelscope.cn/models/Tencent-Hunyuan/Hy-Embodied-0.5-VLA-UMI
Hy-Embodied-0.5-VLA-RoboTwin:https://modelscope.cn/models/Tencent-Hunyuan/Hy-Embodied-0.5-VLA-RoboTwin
Hy-Embodied-0.5-VLA-Data:https://modelscope.cn/datasets/Tencent-HunYuan/Hy-Embodied-0.5-VLA-Data
01
从数据到落地
随着 VLA 模型在机器人连续控制中展现出越来越强的潜力,业界也逐渐意识到,通用机器人能力的形成不能只依赖更大的模型或更强的策略。真实机器人部署需要数据、模型、预训练、后训练和执行系统协同设计,既要能学习复杂操作技能,也要能在真实硬件约束下稳定运行。
HyVLA-0.5 正是在这一背景下提出,目标是推动 VLA 从模型能力验证走向可持续迭代、可跨本体迁移、可真实部署的机器人系统。
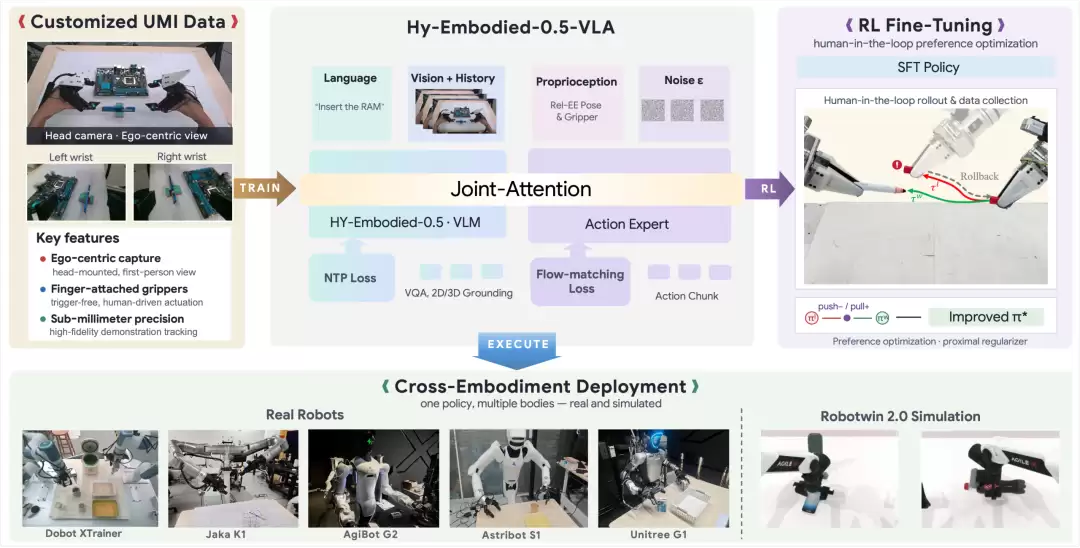
Hy-Embodied-0.5-VLA 的整体系统架构,涵盖数据采集、模型架构、跨本体监督微调、强化学习后训练等关键环节,体现了其从数据到模型再到策略优化的全栈式设计。
数据是机器人基础模型能力的根基。HyVLA-0.5自研了高精度指套式 UMI 数据采集装置,并配套运动捕捉定位,实现了面向人类示教的高保真数据采集。该装置不仅能够记录第一视角视觉信息,还能通过外部光学运动捕捉系统获得亚毫米级 6-DoF 轨迹标注;部分夹爪还集成了末端力 / 力矩传感能力,使数据天然包含可用于力感知、力控学习的物理交互信息。
基于这套自研采集系统,HyVLA-0.5 构建了超过10,000 小时、覆盖 70 类任务、超过 100 万条 episode 的 Hy-UMI-10K 数据集。该数据集涵盖厨房、洗衣、收纳、清洁、工具使用、柔性物体操作等多类日常场景,为学习精细操作、长程任务和跨场景泛化提供了规模化基础。HyVLA-0.5 计划开放其中 2,000 小时自采 UMI 数据,与学术界和产业界共同推进高质量机器人数据、评测与模型训练范式的共研共建。
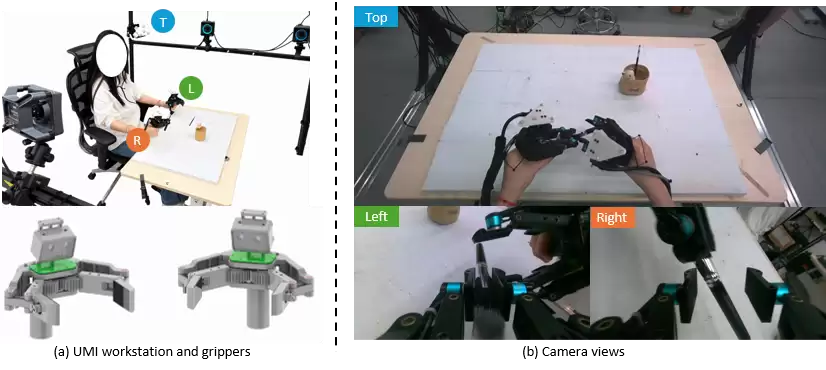
自研 UMI 数据采集工作站
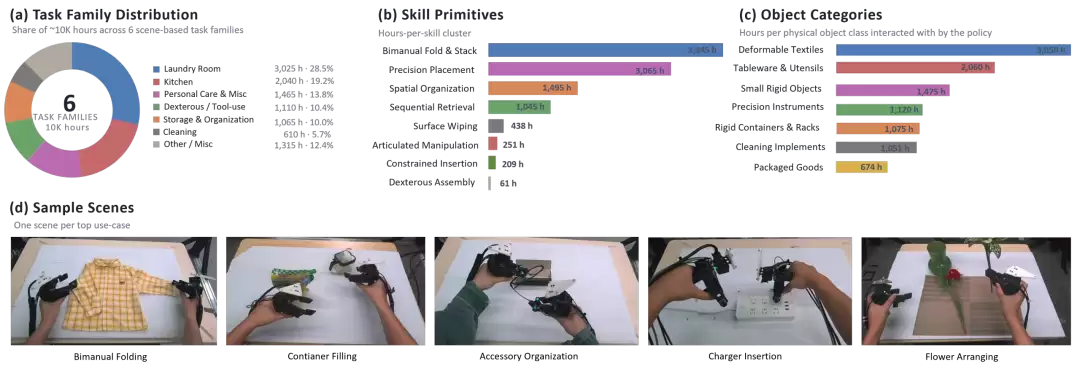
自采 Hy-UMI-10K 数据集组成
在模型侧,HyVLA-0.5 基于腾讯 Robotics X 和混元联合自研的Hy-Embodied-0.5 具身视觉语言模型进行扩展,将其面向视觉语言理解的能力进一步连接到机器人连续控制。系统引入基于流匹配的行动专家模块,直接生成连续动作轨迹;同时通过双塔结构将视觉语言理解与动作生成解耦,使语义感知、空间理解和底层控制能够在统一框架中协同工作。
为了支持真实机器人中的时序感知,HyVLA-0.5 进一步设计了一个紧凑记忆编码器,将多帧、多视角视觉历史压缩为紧凑的当前帧表示,从而在不显著增加视觉 token 数量的情况下引入短时记忆。系统还采用增量式动作块表示,让策略预测相对于当前末端执行器状态的增量动作,从而降低对特定机器人关节结构和运动学的依赖,为后续跨本体迁移和统一部署奠定基础。
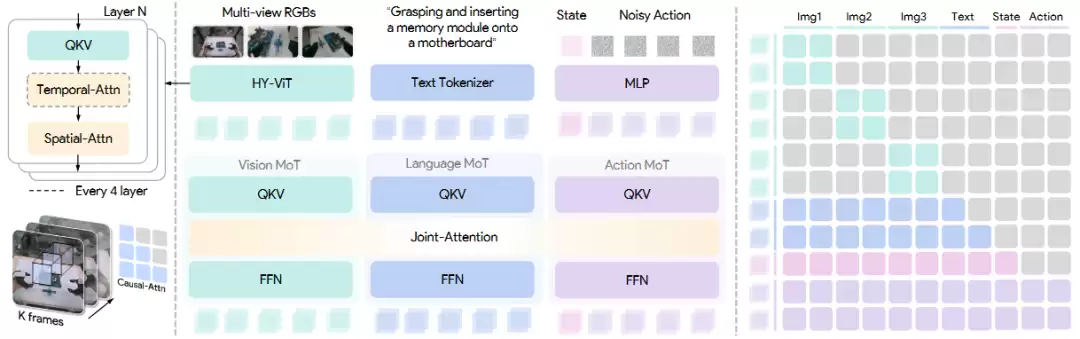
HyVLA-0.5 模型架构。MoT 架构搭建,借助共享联合注意力机制实现多模态信息交互,图像编码器被拓展为轻量化记忆编码器,沿用 Hy-Embodied-0.5 模型的设计思路,引入局部双向注意力对多视角观测信息建模。
在训练流程上,HyVLA-0.5 首先在 Hy-UMI-10K上进行持续预训练,学习来自大规模人类示教的通用行动先验。随后,系统在下游任务上进行监督微调,并将真实机器人评测组织为两条互补的 SFT track:Track-A面向目标机器人适配,即在同一机器人平台上采集示教并部署评测;Track-B面向 UMI-only 跨本体迁移,即只使用任务相关 UMI 示教进行微调,不采集目标机器人遥操作数据,随后部署到形态不同的真实机器人上。
这一设计使 HyVLA-0.5 能够同时验证两类关键能力:一方面,在 Track-A 中评估模型在目标机器人上的精细适配能力;另一方面,在 Track-B 中评估高精度 UMI 数据和预训练行动先验是否能够跨越人类手持采集装置与不同机器人平台之间的本体差异。
实验显示,UMI 预训练不仅在仿真任务中带来稳定增益,在真实机器人任务中收益更为显著,尤其有助于提升精细操作中的关键动作预测质量。更重要的是,高精度 UMI 数据不仅可用于大规模持续预训练,也可以直接作为下游任务的后训练 / 微调轨迹,使模型在无需目标机器人遥操作数据的条件下,仍能在跨本体真机任务中取得较好的部署成功率。
在后训练阶段,团队引入FlowPRO,将Proximalized Preference Optimization(PRO)首次系统性应用到基于流匹配的 VLA 的真实机器人后训练中。与依赖人工设计奖励或学习判别模型的方法不同,FlowPRO 通过真实机器人执行中的干预与回滚机制,直接采集成对的失败轨迹和成功纠正轨迹,并将其转化为可用于离线偏好优化的训练信号。
FlowPRO 的核心是 RPRO loss:它在连续动作生成的流匹配目标中直接对比偏好动作与非偏好动作,使策略在每个状态上向成功纠正动作靠近、远离失败动作;同时通过近端正则项约束策略更新,抑制隐式奖励漂移,降低奖励黑客和灾难性遗忘风险。实验中,FlowPRO 在 Bottle、Cap、USB、Zip 等四个真实双臂任务上持续优于 DAgger 和 PI0.6 * 方案,并在三轮后训练后将多项任务成功率推进到接近天花板水平。
真实部署是从模型走向机器人系统的最后一环。HyVLA-0.5 面向不同机器人平台设计了跨机器人形态的平台映射机制,将模型输出的末端增量动作映射到目标机器人坐标系和逆运动学求解过程,使同一策略接口能够服务于固定基座双臂、类人形机器人等不同形态。
同时,HyVLA-0.5 实现了异步推理与执行框架,将高容量 VLA 的前向推理和机器人伺服执行解耦,通过动作指令缓冲区在推理线程与执行线程之间持续传递动作指令,从而减少推理延迟对机器人连续运动的影响。针对基于动作块策略容易出现的动作边界不连续问题,系统进一步引入延迟感知的三次贝塞尔轨迹拼接方法,在无需额外训练控制器的情况下实现平滑、连续的高频执行。
02
仿真与真机双重验证
在 RoboTwin 2.0 仿真基准上,HyVLA-0.5 在 Clean 和 Randomized 设置中分别达到 90.9% 和 90.1% 的成功率,超过多种同期 VLA 系统。在真实机器人评测中,HyVLA-0.5 覆盖 Dobot X-Trainer、JAKA K1、Astribot S1 和 Unitree G1 等多个平台,验证了同本体适配、跨本体迁移、力感知任务和 FlowPRO 后训练能力。
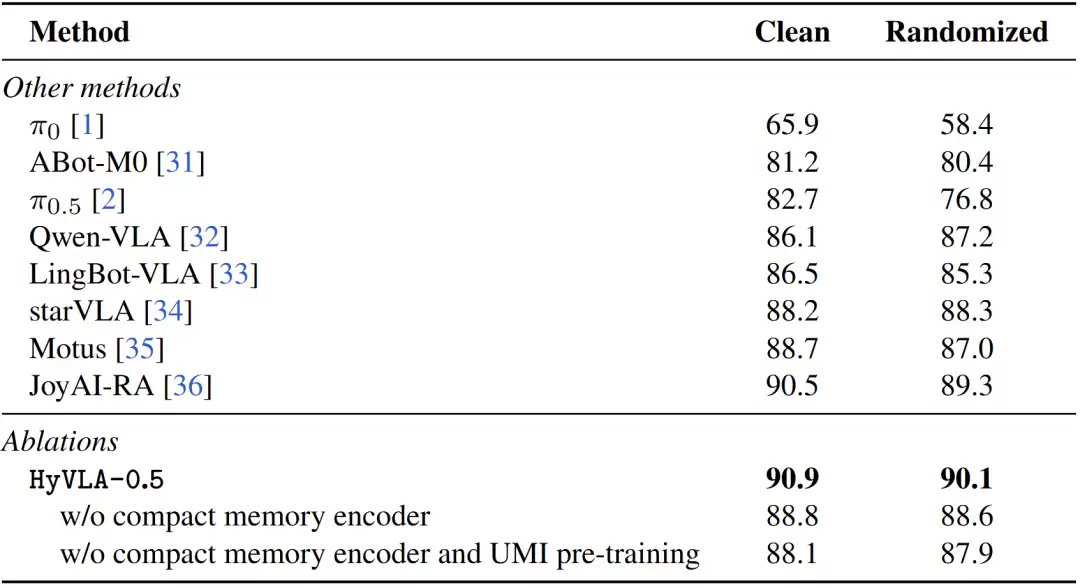
RoboTwin 2.0 仿真测评结果

六个真机任务上的测评结果。Track-A (使用同本体数据微调):使用 X-Trainer 数据微调部署到 X-Trainer 上。 Track-B(使用跨本体数据微调):使用高精度 UMI 数据微调微调部署到 JAKA K1 和 Astribot S1 上
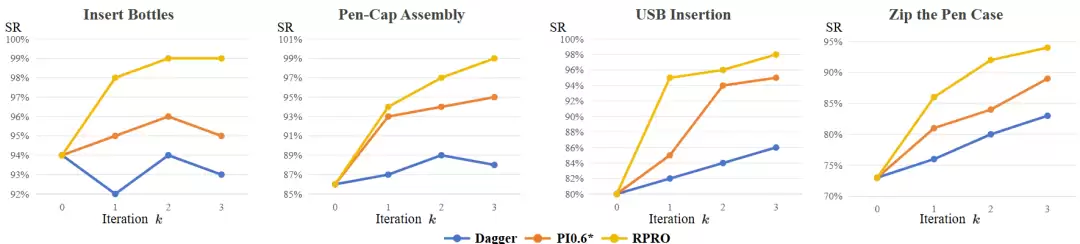
RL 后训练测评结果。以 HyVLA-0.5 作为基础策略,四项真实机器人任务下每轮迭代的任务成功率。第 0 轮迭代对应监督微调模型检查点;第 1–3 轮迭代代表连续多轮后训练过程。
03
本地部署与微调
模型下载:
modelscopedownload --model Tencent-Hunyuan/Hy-Embodied-0.5-VLA-UMI --local_dir Tencent-Hunyuan/Hy-Embodied-0.5-VLA-UMI
代码与环境安装:
gitclone https://github.com/Tencent-Hunyuan/Hy-Embodied-0.5-VLAcdHy-Embodied-0.5-VLA# One-off: install uvcurl-LsSf https://astral.sh/uv/install.sh | sh# Materialize the virtual environmentuvsyncpipinstall -r requirements.txt
import torchfrom hy_vla import HyVLA, HyVLAConfigckpt ="Tencent-Hunyuan/Hy-Embodied-0.5-VLA-UMI"config = HyVLAConfig.from_pretrained(ckpt)policy = HyVLA.from_pretrained(ckpt, config=config)policy.enable_video_encoder_if_needed() # K=1 in pretrain; call this before fine-tuning with K>1policy = policy.to(device="cuda", dtype=torch.bfloat16).eval()# (B, K, C, H, W); K=1 history slot (pre-trained mode)img = torch.zeros(1, 1, 3, 224, 224, device="cuda", dtype=torch.bfloat16)# Normalized dual-arm EEF: [xyz(3) + rot6d(6) + gripper(1)] * 2state = torch.zeros((1, config.max_state_dim), device="cuda", dtype=torch.bfloat16)batch = { "observation.images.top_head":img, "observation.images.hand_left": img, "observation.images.hand_right": img, "observation.state": state, "task": ["pick up the bottle"],}with torch.no_grad():actions = policy.forward_evaluate(batch)["pred"]actions = actions[..., : config.action_feature.shape[0]]print(actions.shape)
官方仓库支持模型微调
# Fine-tune on RoboTwin 2.0exportCHIEF_IP=bashscripts/train_robotwin_umi.sh
有关监督微调(SFT)的具体步骤,请参阅:https://github.com/Tencent-Hunyuan/Hy-Embodied-0.5-VLA
04
腾讯Robotics X的开源矩阵
回看 2025 至 2026 年,腾讯 Robotics X 联合混元团队已构建起从底层平台基础设施到行业多模态大模型的完整开源矩阵。此前发布并开源的HY-Embodied-0.5系列,是一套面向真实世界具身智能体的基础模型,重点增强空间和时间视觉感知,以及预测、交互、规划等具身推理能力;相比通用视觉语言模型,它更像为机器人任务重新设计的多模态底座,关注的不只是图像问答,还有空间定位、时序理解和任务推理。随后发布的增强版HY-Embodied-0.5-X继续围绕"看得懂、想得清、做得到"的闭环专项优化,强化精细操作理解、空间推理、动作预测、风险判断、多模态指代里解和长程规划。此外,腾讯还开放了自研机器人本体互连术RoboFusion,以 IP 协议为基础定义本体通信、融合机器人多业务数据传输,赋予机器人更高级的软件重构、软件定义特征;在示范机器人系统上,它将线束从 35 束减少到 3 束,相当于消除 32 条独立通道的布线负担,对本体互连而言是一项革命性跨越。
更早之前,从 2025 年开始,腾讯 Robotics X 实验室的重心明显转向软件算法与 AI 模型研发,并强调开源开放共享。同年,实验室联合福田实验室推出Tairos(钛螺丝)具身智能开放平台,面向机器人本体厂商和应用开发商,以模块化方式提供大模型开发工具与数据服务,首批集成多模态感知模型、规划大模型、感知-行动联合大模型等核心组件,并提供仿真平台、数据服务和 SDK 接口。腾讯首席科学家、Robotics X 实验室主任、福田实验室主任张正友博士曾提到,Tairos 基于规划大模型、感知模型、感知行动联合大模型结合的 SLAP³ 理论构建,本质是为机器人本体开发商和应用开发商补齐关键软件能力。
这类开放能力对厂商的价值很直接:本体厂商擅长机械结构、电机控制、供应链和硬件量产,应用开发商熟悉场景,但都很难独立完成从数据采集、模型训练到仿真验证与硬件适配的全链路。Tairos 与 HY-Embodied 系列正是要降低这部分门槛,让更多厂商接入一套相对成熟的"大脑"能力。过去很多机器人 demo 看起来惊艳,一旦进入开放环境就迅速暴露不足;机器人要从展台走向工厂、商超、家庭和服务场景,靠的不会只是某一个更强的模型,还需要一套能持续迭代的软件体系。短短一年间,从 Tairos 到 HY-Embodied-0.5、HY-Embodied-0.5-X,再到 Hy-Embodied-0.5-VLA,腾讯补齐了平台、模型、数据、训练和部署等关键环节,每一步都有真实工程产出,也都选择开放给行业——把算法、模型和平台能力,沉淀为更多机器人厂商可以接入的大脑底座。
05
写在最后
点击阅读原文,直达模型详情~
?点击关注ModelScope公众号获取
更多技术信息~
阅读原文
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]