




零代码打造AI模拟面试官:天工AI全行业面试题库指南
2026-06-14
2026-06-19 0
原创 NLPer 2026-06-17 10:49 江苏

GLM 大模型发布并开源 GLM-5.2,这是 GLM-5 系列面向长程任务的一次重要更新。
今天上午,智谱 GLM 大模型发布并开源 GLM-5.2。
这是 GLM-5 系列面向长程任务的一次重要更新。模型定位围绕 1M 上下文、Coding Agent、工具调用、项目级工程理解和长任务稳定执行展开。GLM-5.2 要回答的问题也很直接:当 AI 的工作从一句回答、一个函数,推进到读完整项目、连续修改、调用工具、跑验证、处理失败并交付结果时,模型还能不能在很长的上下文和很长的执行链里保持稳定。
最近模型发布里,这条线越来越清晰。过去开源模型常常围绕单轮问答、数学、代码题、通用榜单来竞争;现在 Claude Code、Codex、Gemini CLI、Qwen Code、MiMo Code 都在把模型往真实开发流程里推,GLM-5.2 也是这条线上的新进展。
GLM5.2 模型权重在 Hugging Face 和 ModelScope 上线,GLM-5 仓库提供下载入口、本地部署说明和技术报告链接;API 模型名是glm-5.2;ZCode、chat.z.ai、ChatGLM、AutoGLM 也都放进了这次产品入口里。模型页标注 MIT 许可证,GLM-5 仓库代码页面显示 Apache-2.0;仓库下载表里,GLM-5.2 标为744B-A40B,提供 BF16 和 FP8 版本。

GLM-5.2 最突出的关键词是 1M 上下文。
长上下文过去已经被很多模型写进参数表。难点在于,能塞进 100 万 token 和能在 100 万 token 里稳定干活,是两件事。真实工程任务里,模型要持续处理项目结构、接口约定、历史修改、测试结果、报错信息、用户偏好和约束条件。
GLM-5.2 的使用场景也明显偏工程:移动开发、项目级工程接管、长文档理解、外部工具调用、MCP、结构化输出。原文里给了一个更直观的例子:让模型处理 88 万 tokens 的上下文,完成一个覆盖 Web、移动端和小程序的完整应用。
对开发者来说,1M 上下文的价值主要体现在三个环节。
| 环节 | 对长任务的影响 |
|---|---|
| 项目读取 | 大型仓库里的前端、后端、配置、测试、文档和历史实现可以放进更完整的上下文 |
| 状态保留 | 多轮修改、命令输出、报错信息和已经通过的判断更容易留在同一条任务链里 |
| 工具协作 | Function Call、Context Caching、Structured Output、MCP 等能力可以进入更完整的 Agent 系统 |
这个问题落到任务中后段会更明显。很多 Agent 任务开头都很顺,压力来自已经改了很多文件、跑了几轮命令、遇到多次失败之后。此时模型如果忘掉之前的判断,很容易重复踩坑,或者把已经正确的部分改坏。
GLM-5.2 的模型介绍里,Coding 被放在主线位置。
GLM-5.2 面向 long-horizon tasks,相比 GLM-5.1 在长程任务能力上有明显提升,并首次把这类能力放到稳定 1M-token context 上。GLM-5.2 在 Terminal-Bench 2.1 上为 81.0,GLM-5.1 为 62.0;SWE-bench Pro 上为 62.1,GLM-5.1 为 58.4。
GLM5.2 还提到几项更偏长程工程的评测:FrontierSWE 上距离 Claude Opus 4.8 约 1 个百分点,SWE-Marathon 上仍落后 Claude Opus 4.8 约 13 个百分点;Code Arena 盲测前端开发榜单中,GLM-5.2 位列全球可用模型前列。
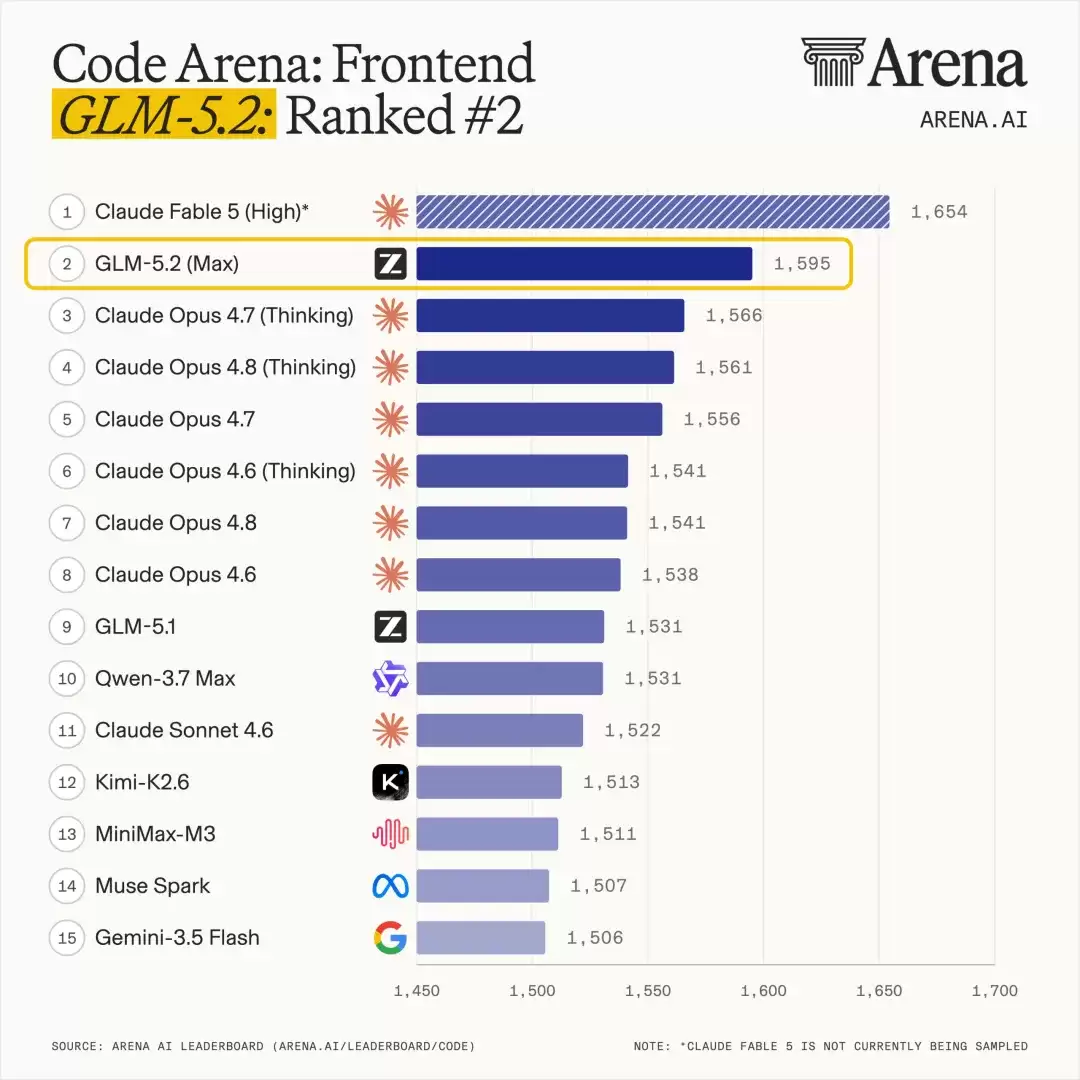
| 维度 | 结果 |
|---|---|
| Terminal-Bench 2.1 | GLM-5.2 为 81.0,GLM-5.1 为 62.0 |
| SWE-bench Pro | GLM-5.2 为 62.1,GLM-5.1 为 58.4 |
| Claude Opus 4.8 对比 | Terminal-Bench 2.1 上接近 Claude Opus 4.8 的 85.0 |
| FrontierSWE | 距离 Claude Opus 4.8 约 1 个百分点 |
| SWE-Marathon | 仍落后 Claude Opus 4.8 约 13 个百分点 |
| Code Arena | 前端开发盲测榜单中位列全球可用模型前列 |
这类评测比普通代码题更接近真实开发流程。Terminal-Bench 看终端任务,SWE-bench Pro 看软件工程修复,FrontierSWE 和 SWE-Marathon 继续把任务拉长。它们共同指向一个问题:模型能不能读环境、理解仓库、写代码、跑命令、处理失败、继续迭代。
这正是 Coding Agent 和传统代码补全最大的区别。代码补全更像一个局部助手,给当前文件、当前函数、当前光标附近补几行;Coding Agent 要接住的是一个项目任务,过程里会有计划、修改、验证、回滚和再尝试。GLM-5.2 把长上下文、工具调用和长程执行放在一起,实际瞄准的就是这个方向。
这次发布给出模型权重的同时,也把 ZCode 放到了很显眼的位置。
ZCode 产品页写着“ZCode 3.0 深度适配 GLM-5.2”。它的定位是把 AI Agents 接入开发者已有工具链,覆盖规划、编码、评审和上线。页面展示里可以看到任务、工作区、分支执行、文件写入、验证、提交等动作,形态更接近 Claude Code、Codex 这类开发者 Agent 工具。
这点对开发者读者很重要。GLM-5.2 的开源权重决定了它能不能被研究、部署和二次开发;ZCode 这类产品入口决定了普通开发者能不能把模型放进日常工作流里。前者影响模型生态,后者影响真实使用。
开发者可以把 GLM-5.2 的体验拆成两条线看。一条是模型线:下载权重、看仓库说明、跑本地推理、接 API、做 benchmark 和任务测试。另一条是产品线:用 ZCode 或 chat.z.ai 直接体验长任务、项目级代码理解、工具调用和多轮修改。模型线决定可控性和可复现性,产品线决定交互体验和实际效率。
GLM-5.2 的更新范围覆盖了模型参数之外的多层工程。
第一是 IndexShare。GLM-5.2 在长上下文推理上复用每四层稀疏注意力的 indexer,让 1M context 下的单 token FLOPs 降到 2.9 倍。IndexCache 论文讨论的是跨层复用索引来加速稀疏注意力推理,目标是降低长上下文推理成本和显存压力。
第二是 MTP speculative decoding。GLM-5.2 改进了 MTP 层,acceptance length 最多提升 20%。这类优化影响的是生成速度和推理效率,尤其是在长任务和长输出场景里,推理成本会直接决定模型能不能被频繁使用。
第三是 slime。GLM-5 技术报告把模型路线描述为从 vibe coding 走向 agentic engineering,并提到异步强化学习基础设施和长程交互学习。slime 仓库把自己定义为面向 RL scaling 的 LLM post-training framework,核心能力包括连接 Megatron 与 SGLang 做高性能训练,以及通过自定义数据生成接口组织训练数据生成流程。
| 工程环节 | 相关信息 | 对长任务的意义 |
|---|---|---|
| IndexShare | 每四层稀疏注意力复用同一个 indexer | 降低 1M 上下文推理的计算开销 |
| MTP speculative decoding | acceptance length 最多提升 20% | 改善长输出和长任务里的推理效率 |
| slime / Agentic RL | 面向 RL scaling 的后训练框架 | 支撑模型从长程交互中学习 |
| 国产算力适配 | 昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等平台被列入 Day 0 推理适配 | 让开源模型更容易进入国内硬件生态 |
GLM-5.2 这次发布,把智谱的新模型放到了一个很明确的位置:面向长程任务的开源基础模型,重点服务 Coding Agent 和项目级工程工作流。
这次发布的看点很集中:1M 上下文、GLM-5 系列仓库里的744B-A40B权重入口、MIT 模型许可、API 模型名glm-5.2、ZCode 产品适配、长上下文推理优化、Agentic RL 基础设施和国产算力适配。
后续最值得验证的也很具体:在真实项目里,GLM-5.2 能不能长时间保持上下文;能不能稳定调用工具并完成验收;能不能在本地或国产算力上跑出可接受的成本;ZCode 这类产品入口能不能把模型能力转成开发者每天能用的工作流。
如果这些问题能被持续验证,GLM-5.2 的意义会超过一次常规开源版本更新。它代表国产开源模型开始把竞争场景从单轮回答,推向更长、更复杂、更接近真实工作的 Agent 任务。
Z.ai GLM-5.2 发布页:https://z.ai/blog/glm-5.2
GLM-5 GitHub 仓库:https://github.com/zai-org/GLM-5
GLM-5 中文说明:https://github.com/zai-org/GLM-5/blob/main/README_zh.md
Hugging Face 模型页:https://huggingface.co/zai-org/GLM-5.2
ModelScope 模型页:https://modelscope.cn/models/ZhipuAI/GLM-5.2
GLM-5.2 API 文档:https://docs.z.ai/guides/llm/glm-5.2
chat.z.ai:https://chat.z.ai
ChatGLM:https://chatglm.cn
ZCode:https://zcode.z.ai/cn
AutoGLM:https://autoglm.zhipuai.cn
GLM-5 技术报告:https://arxiv.org/abs/2602.15763
IndexCache 论文:https://arxiv.org/abs/2603.12201
slime 仓库:https://github.com/THUDM/slime
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点

关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。

Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]