




《猫猫钓游记》可爱+收集+钓鱼游戏试玩
2026-06-30
2026-07-01 0
城市轨道交通系统的复杂度,决定了它的数据是个“超级难题”。一条线路是“线”,但它由上千个空间坐标连续的“里程点”构成。车站是“点”,却有站厅、站台、换乘通道等至少三层结构。设备是“物”,如一个风机,既属于某个车站,又属于某个环控系统,还受某台PLC控制,其数据是立体的关系网络。传统信息化擅长的树状结构,描述不了地铁这种多维度时空拓扑网络。一个“车站”在信号、AFC、机电系统中的编码、命名、颗粒度完全不同。更麻烦的是语义鸿沟,“站台”在信号和屏梯系统里指的可能不是同一实体。这种割裂不只是技术问题,更是百年工业史形成的组织、知识与供应商生态壁垒。另外一方面,“乘客服务好”不等于“数据管理好”,顶尖的乘客服务体验,是出色的商业与运营公司,并不是原生数字企业。优势在于流程和执行力。即使是在“建设-运营”数据移交上做得全球领先,但仍没有彻底解决数据统一视图的问题,也同样会面临着老旧系统与新型数字应用的集成痛苦。其次,极致的可靠性,的本质很可能来自极致的“不变”。物理系统产生的数据天然是孤岛,用管理流程而非系统集成来协同,是成本、风险最低的方式。可预测的“不集成”,远好于脆弱的“强集成”,有的时候过度追求信息化反而是引入了不可控风险。港铁的“精”、东京地铁的“稳”、巴黎地铁的“老”,各自的成功路径,可能也恰恰成了它们进行根本性数字化转型的最大惯性。最困难的不一定是技术问题,可能是以物理系统建设与运营为核心的思维惯性、组织架构或生态模式,乃至无数个无法适应数字时代的一体化要求。

物模型提炼模式
物模型设计是从决策到检查的完整闭环。本质并不是机械地“定义字段”,而是定义一台设备在数字世界中的表达能力。我提供三种从思考到落地的建模方式,提供给行业人士参考。三种不同维度所给出的解决方案有的时候也可以看成是共同构成了一个完整的物模型治理体系,只是不同阶段的定义差异将其看成是一个管“族谱怎么写”,一个管“家怎么分”,一个管“语言怎么进化”。
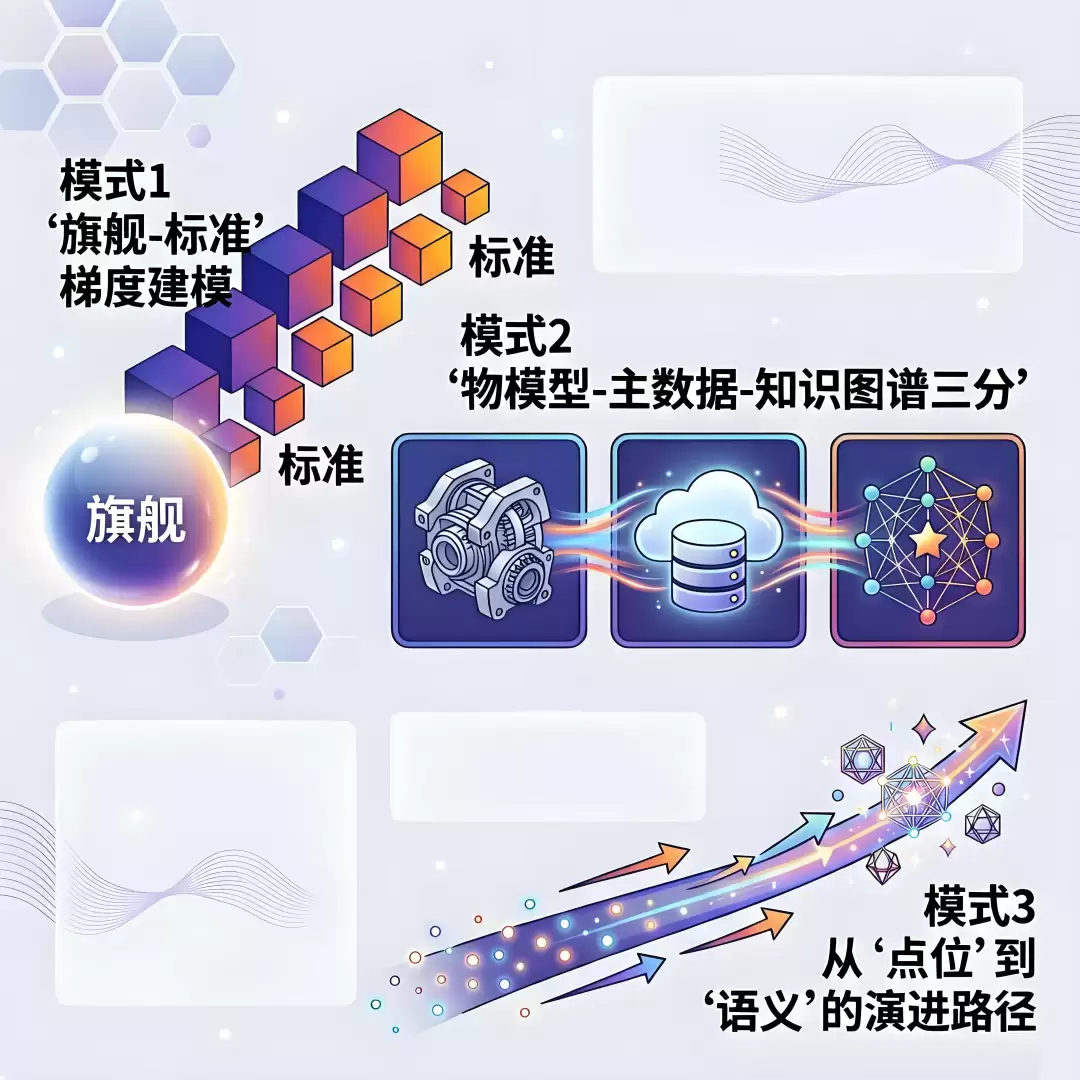
模式1:“旗舰-标准”梯度建模,核心命题是如何在“统一标准”和“个性扩展”之间找到平衡点?
1. 提炼的重点:
旗舰(Flagship):不是选销量最大的,而是选功能最全、结构最复杂的那个设备类型作为标杆。比如闸机家族里,肯定选功能最全的扇门模型当旗舰。
最小公共集(Minimal Common Set):从旗舰中剥离其独有属性,保留所有子类型都必须有的属性和服务,形成“标准化骨架”。
扩展字段:各子类型在骨架上长出自己的肉。AGM挂数字量点位,SCPF挂模拟量,互不干扰。

2. 差异与核心价值:
它解决的是同品类设备碎片化的问题。没有这个模式,每个设备类型都会被单独建模,彼此没有继承关系。这意味着,今天你想统计“全站所有闸机的开关次数”,如果扇门的叫door_cycle_count,剪式门的叫scissor_cycle_count,你就得写两套完全不同的查询逻辑。这个模式的价值,是用“继承”机制强制推行了“同类设备的最小公约”。
模式2:物模型-主数据-知识图谱 三分,核心命题是不同性质的数据,需要严格判断是否应该混在一起?
1. 提炼的重点:
这是三个模式里最顶层、也最容易被误解的一条。它的核心是严格划分数据疆域:
物模型:只负责设备的实时运行表现。它像设备的心电图,回答“此刻我怎么样”。
主数据:只负责设备的静态身份档案。它像设备的身份证和户口本,回答“我是谁,我属于谁,我在哪”。
知识图谱:只负责跨设备、跨类型的规律与知识。它像医生的教科书和经验集,回答“这种情况意味着什么,该怎么处理”。
2. 差异与核心价值:
它解决的是数据纠缠。许多人会把“风机安装在B2层”也当成属性写进物模型。后果是,当风机位置变更时,你不得不去改风机的物模型定义(相当于为了一次搬家去改身份证的底层格式),这极其荒谬。
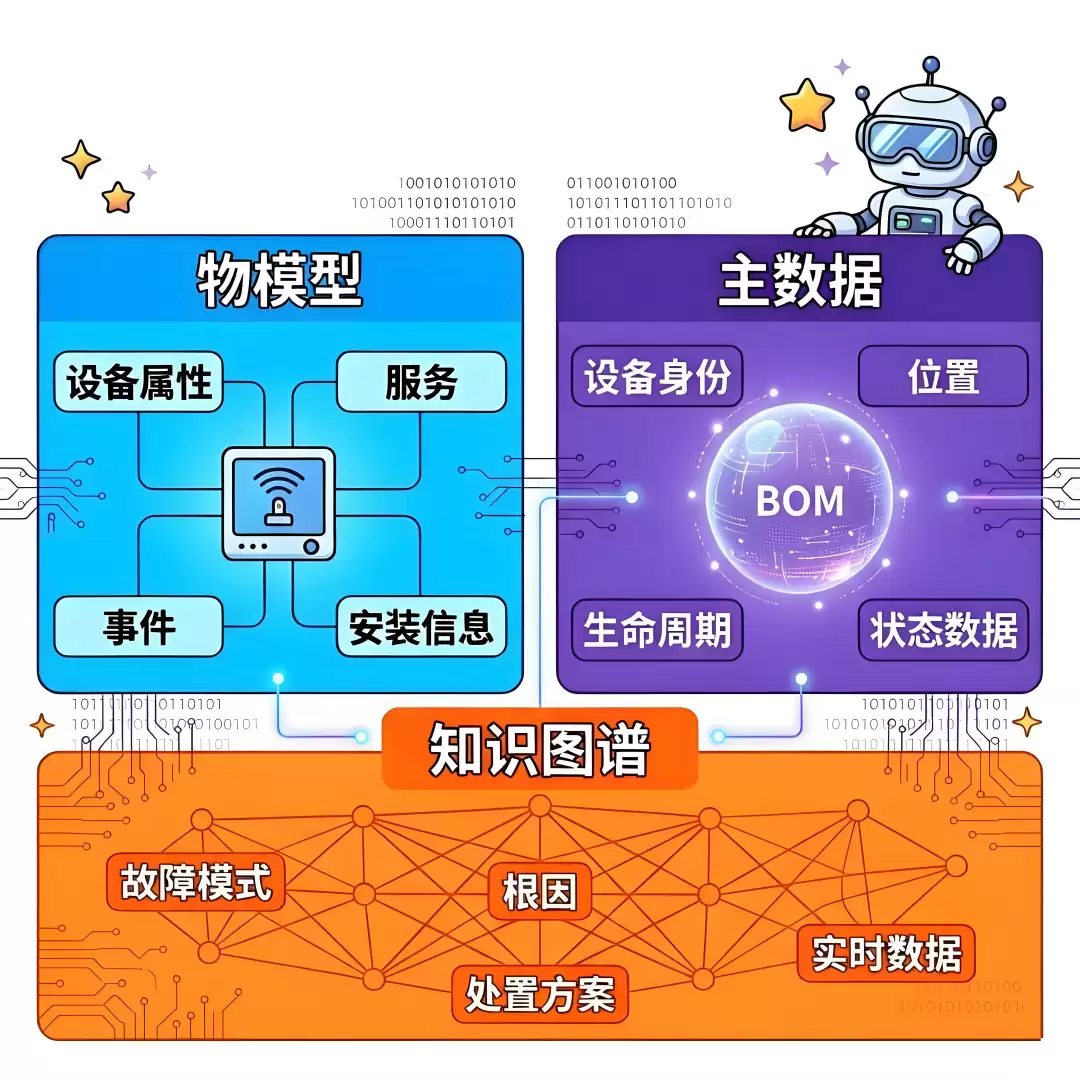
这个模式的价值,是防止“变化频率”和“数据用途”完全不同的信息耦合在一起,从而让每一层都可以独立演进。 物模型每秒变一次,主数据十年变一次,知识图谱需要专家持续修正——它们的治理节奏截然不同,必须分层。
模式3:从“点位”到“语义”的演进路径,核心命题是如何带着无法抛弃的历史包袱,走向智能化?
1. 提炼的重点:
这是一条务实的、分三步走的进化路径:
第一阶段:点位化。老旧设备的原始状态,只能告诉你“1号引脚通了”这样的物理信号。有数据,无含义。
第二阶段:语义化。给物理信号贴上业务标签,di_d01 = 1 变成了 door_status = OPEN。有含义,无洞察。
第三阶段:智能化。在语义基础上进行计算和衍生,door_status经过模型计算,产出 door_degradation_score = 85。有洞察,可预测。
2. 差异与核心价值:
它解决的是新老系统并存时的数字化方言问题。老设备说方言(点位),新平台只能说普通话(语义),直接对接就是鸡同鸭讲。
这个模式的价值,是承认老设备改造的局限性,不搞一刀切的“推倒重建”。 它用边缘网关当“翻译器”,将老设备的方言实时翻译成普通话上报。这既保护了存量资产的投资,又确保了新平台的语义纯净度。
在定义一个属性前,设计决策树就是一个标准的六步追问:是准备在物模型中新增一个属性时,必须按照顺序逐级对自我的拷问。这不是流程,而是防波堤。
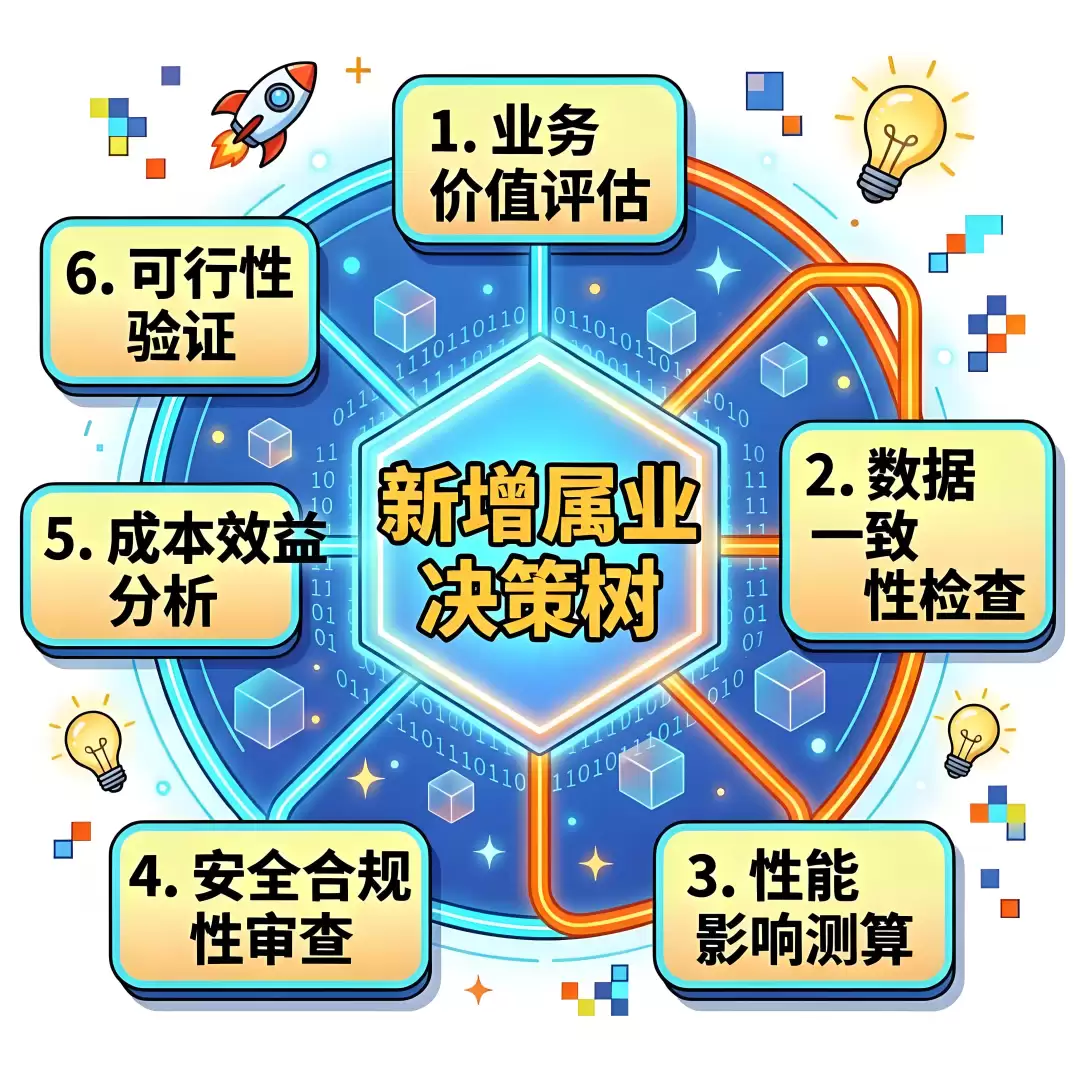
Step 1:这个属性是必要的吗?
数据不是石油,不是越多越好。海量无用数据的存储、传输、展示、维护成本,会像暗流一样持续吞噬系统性能和团队精力。物模型会像圣诞树一样挂满“也许有用”的字段。一年后,没人知道reserved_field_07是干什么的,但谁也不敢删。数据库臃肿,采集负载无谓增高,而真正关键的字段却被淹没在海量冗余中。垃圾进,垃圾出,决策被噪音稀释。
有谁需要用这个数据?用在什么页面或功能上?
没有这个数据,决策会受影响吗?
如果两个答案都是“没有影响” → 删掉。 不要为了“可能有用”而堆砌垃圾数据。
Step 2:它属于哪一层?
将不同分类信息塞进一个模型,就像把身份证、病历和心电图全部画在同一张纸上,既画不下,也改不动,更没人看得懂,这简直就是一场灾难。如果不能明确,当想修改一个“安装位置”字段时,就不得不重新发布整个物模型版本。当你想查询“此类设备的常见故障模式”时,不得不去翻每台设备的实时数据流。层次混乱,任何变更都伤筋动骨,任何查询都大海捞针。
实体层(Instance):这台设备自己的身份数据,如序列号、安装位置。→ 这不该在物模型里,该去主数据。
类型层(Type):这类设备的共有知识,如BOM模板、故障模式。→ 这是知识图谱的范畴。
实时层(State/Counter):需要高频采集的运行数据。→ 这才是物模型的核心地盘。
Step 3:数据格式对吗?
这是对“机器可读”和“人类可读”的双重承诺。如果不这样做的后果就是机器解析报错,人类理解靠猜。一个值为“3”的状态码,到底是“故障”还是“维护中”?每个人都会根据自己的理解去写代码,系统里充满了针对同一字段的不同解读逻辑,语义一致性彻底崩盘。
dataType能否完整表达其值域?——如果值是0到2000,别用0到255的tiny int。如果值是“开/关/故障”,别用布尔。机器的每一次误解,都是从类型不匹配开始的。
description能让一个新人看懂吗?——不是给自己写的备忘录,是给三个月后接手的新同事,或另一个团队的开发者的标准说明书。写清楚“这是什么,从哪来,什么时候会变”。
Step 4:它怎么被采集?
如果只是单纯的被定义,没告诉系统怎么去拿,等于没定义。一旦没有识别清晰就会导致:关键告警延迟上报,错过了最佳处置窗口。无意义的配置信息却每秒上报,占满带宽,存储成本飙升。该快的没快,该慢的没慢,整个数据供应链的节奏全乱了。
放在哪个策略里?——是每1秒必须上报的“紧急情报”,还是每5分钟更新一次的“常规状态”,还是设备启动时上报一次的“出生证明”?
采集周期合理吗?——高频采集一个十年不变的配置信息,是浪费带宽和存储。低频采集一个故障报警信号,是错失战机。采集策略,就是对信息时效性的承诺。
Step 5:它会被怎么用?
在设计阶段就预埋好数据“被消费”的管道。一个数据从出生那一刻,就应该知道它要去哪。而不是采集了一大堆数据,但告警系统不知道要看哪个,PHM模型不知道要用什么,配置变更绕过了审批直接生效导致事故。数据被生产出来了,却在仓库里烂掉,没有进入任何一个决策闭环。
状态量:谁消费它?告警阈值是多少?
累积量:PHM用它追踪什么?额定寿命是多少?
配置量:多久变一次?变更需要审批吗?
Step 6:它有安全标签吗?
这是最后的底线思维。不是所有数据都生而平等,有些数据泄露或篡改的后果是灾难性的。如果一个可远程复位设备的指令字段,被标记为普通“参考”数据,没有加密传输,没有操作审计。一旦被恶意利用,可能导致运营中断。安全不是加把锁,而是从定义数据的那一刻起,就给它赋予正确的“涉密等级”。
criticality 是 critical 还是 reference?
安全相关字段:等保三级需要它吗?传输加密了吗?
设计是意图,检查是现实。 意图和现实之间永远有鸿沟。三模式,让我们树立正确的架构,但架构正确不等于每一个字段都正确。只有这份“不打勾,不发布”的检查清单,才把一切哲学和原则,变成了一道物理闸门。 它不依赖设计师的天才、不依赖开发者的细心、不依赖评审的记忆。它是一份冷冰冰的、不可跳过的最低标准。
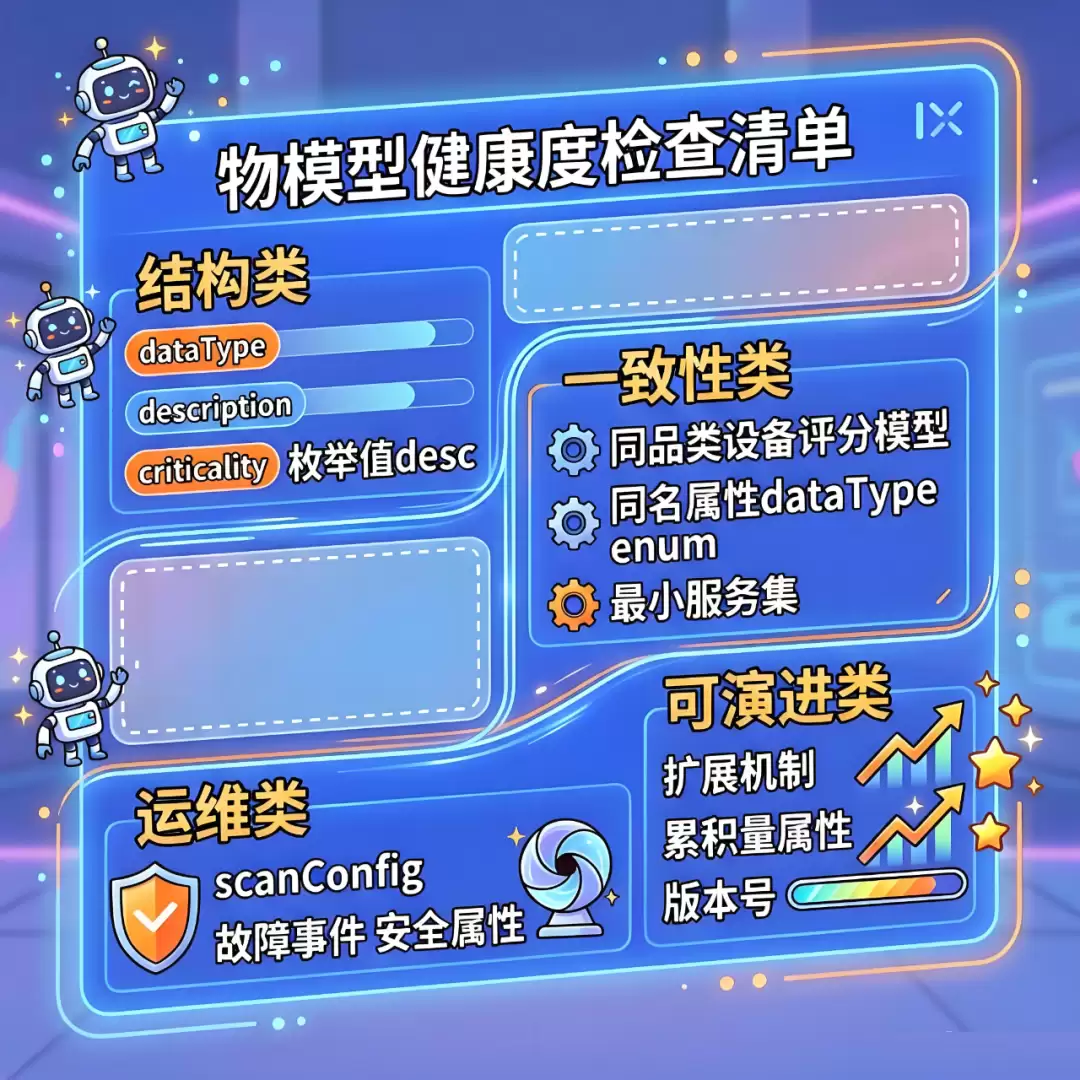
而最终浓缩在结构上的每一个字段一个含义,类型都必须匹配,只将描述留给人类。在一致性上,同品类共享骨架,同名属性同定义,服务能力有基线。在运维上,每样东西都要被采集,故障要有全生命周期事件,安全属性不能缺失。本质上是在构建一套数字世界的信任机制:让系统能相信设备“说”的话,让算法能相信数据的含义,最终让管理者能相信分析得出的结论。智能化转型的万丈高楼,其地基正是这种朴素而坚定的数据表达能力。健康检查是发布前的最后一道防线。每次物模型发布前,需要逐项对照打勾。不打勾,不发布。这些并不是技巧,而是把一次性的设计智慧,变成可持续的、不依赖天才的工程质量。同时也构建了一个信任的三级火箭。
结构类,打造的是机器与机器之间的信任。机器不懂模糊,不懂“差不多”。当door_status今天是整数、明天是枚举时,所有消费这个字段的算法都在赌命。结构的确定性,是机器对话的语法。这是笛卡尔式的清晰——在机器世界里,不存在“语境”这种补救措施。一个误解就会导致连锁错误。所以必须在定义时,就用最死板的格式消灭一切歧义。最终是让每一条数据从诞生那一刻起,就是“合法”的。不依赖下游使用者的“聪明”去猜测和纠正。
每个属性的 dataType 能完整表达其值域
description 不重复,提供 name 之外的额外信息
所有属性有 criticality 标记,无缺失
枚举值的 desc 字段中英双语(如有国际化需求)
一致性类,同品类设备使用同一套评分模型。本质就是在系统与系统之间建立信任。当五条线路、三家供应商的闸机都遵守同一套骨架时,“全路网闸机健康度”的统计才有了意义。否则,你只是在统计一堆不可比较的个案。这是康德的“共通感”——数据要成为公共知识,必须建立在先验的共同框架之上。没有这个共同框架,各系统永远在自说自话。也只有这样才确让跨系统、跨线路的数据对比和汇聚成为可能。这是从“单设备管理”走向“全网智能”的前提。
同名属性在同品类中 dataType 和 enum 完全一致
最小服务集已实现:remote_reset、self_diagnosis、time_sync、set_service_mode 四个服务必须存在
可演进类构建的是人与系统之间的信任。定义了但不采集,等于说谎。故障只报发生不报恢复,等于记黑账。安全属性缺失,等于把家门钥匙挂在门框上。这是实用主义的闭环——一个想法再完美,如果没有在物理世界中运行完整,它就不算真实。运维闭环是对“知行合一”的工程化表达。让系统在持续运行中始终可信。管理者看到的每一份报告,背后都有完整的采集链、事件链和安全链在兜底。
扩展机制已定义,无残留的自由JSON字段
累积量属性已包含,至少有一个可支撑PHM的计数器
版本号反映实际变更历程,不跳号、不回溯
运维类,是三道闸,是对“每样东西都被采集”的兑现——没有采集策略的属性,是幽灵字段。故障全生命周期,是“发生-恢复-退化”的兑现——只有闭环的事件,才能算出真实的可用性。安全属性,是“安全不能缺失”的兑现——tls_version和cert_expiry_days是设备网络安全的底线。
scanConfig 覆盖所有属性,无一遗漏
故障事件覆盖“发生 → 恢复 → 退化”全生命周期
安全属性已包含,至少 tls_version 和 cert_expiry_days
这就是闭环:从“想清楚”,到“做正确”,再到“验证过”。 有了这个闭环,物模型的质量才从一个“手艺活”,变成了一项“工程能力”。这才是“朴素而坚定的数据表达能力”的真正落地。
------------------- END-------------------
本文参与腾讯云自媒体同步曝光计划,分享自微信公众号。原始发表:2026-06-29,如有侵权请联系[email protected] 删除Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]