




《猫猫钓游记》可爱+收集+钓鱼游戏试玩
2026-06-30
2026-07-03 0
企业AI从模型竞争转向数据底座建设,OceanBase为Agent时代重构数据库架构。核心内容:1. 企业AI应用瓶颈从模型转向数据治理与上下文完整性2. 数据库在Agent时代面临多模态处理与实时交互新挑战3. OceanBase AI数据库的四大特性与解决路径
大家好,我是 Ai 学习的老章
众所周知,我本职工作是在公司做 AI 基建,所以大家会看到我写过很多算力、推理引擎、模型部署和评测相关的内容
刚看了 OceanBase AI 数据库的线上发布会,看过之后收获很大,回答了我的一个疑惑:当数据库的主要使用者慢慢从人变成 Agent,企业的数据底座到底该往哪儿长?
我现在越来越认同一个判断
企业 AI 往前走,卡点已经越来越少出在模型本身,更多会落到数据这一层
上下文够不够完整,非结构化数据能不能进治理,搜索结果准不准,Agent 试错会不会污染生产环境,这些问题如果压不住,AI 应用就很难真正跑进核心业务
过去我们聊数据库,最常说的是高并发、事务、容灾、成本、性能
到了 Agent 时代,问题突然多了几层:
这时候,数据库如果还只是人类点开后台查表的地方,就不太够了
OceanBase 这次给出的主口径是:
OceanBase AI 数据库 = 湖库一体 · 多模态 · AI 原生
OceanBase 想做的,是给企业 Agent 准备一套真正能进生产的数据底座
OceanBase 对 AI 数据库的定义,核心落在四个词上:一体化、多模态、Agent 友好、开放

过去三年,企业 AI 的预算大多花在模型和算力上
买模型、接 API、建知识库、做智能客服、上 Copilot,这些都很热闹
但真正跑进业务流程之后,很多项目会发现一个很尴尬的问题:
大模型越来越强,业务价值却经常卡在数据上
因为大模型本身解决的是通用智能问题,企业要的是业务智能问题
通用智能会说话、会推理、会生成
业务智能还要知道:
这些答案都在企业数据里
所以 OceanBase 这次反复强调一个变化:数据库的使用者正在从人变成 Agent
人用数据库的时候,大多是明确查询
查一条订单
看一张报表
筛一批异常记录
Agent 用数据库的时候,动作要复杂得多
先理解上下文
再混合检索
再调用工具
再写入状态
再根据结果继续下一步
失败之后还要回滚
成功之后还要沉淀经验
这就把数据库从后台系统,推到了 Agent 工作流的正中央

第一,企业的数据形态已经变了
过去数据库主要管结构化数据,表、行、列、字段
现在 Agent 要吃的上下文里,有合同 PDF、客服录音、会议纪要、体检报告、商品图片、行车视频、风控规则、知识库片段、对话记忆、向量、JSON
这些东西如果还散落在对象存储、文件系统、搜索引擎、向量库、业务库之间,Agent 每做一步都要跨系统拼上下文
拼一次,就多一次延迟
搬一次,就多一份冗余
同步一次,就多一个一致性风险
第二,企业的数据流动方式也变了
传统链路经常长这样:
交易库 → ETL → 数仓 / 数据湖 → 搜索引擎 / 向量库 → RAG / Agent
这条链路能跑,但它很慢,也很重
Agent 产生 bad case、用户反馈、执行轨迹之后,如果要等几天才被离线分析挖出来,再回到线上验证,这个飞轮就转不快
OceanBase 的说法是数据飞轮:Agent 产生数据,数据回流优化模型和知识,优化后的能力再服务业务
飞轮转得快,AI 才会越用越准
第三,Agent 会带来新的风险
人改生产数据之前会犹豫,Agent 很可能直接开干
尤其在企业里,Agent 会越来越多地执行生产任务,写数据、改流程、调工具、做评测
这时候数据库要给它准备安全边界
它可以试错,但不能污染生产
它可以并行,但不能互相踩脚
它可以失败,但失败之后要能快速丢弃、回滚、重来
这也是我觉得 OceanBase 这次最值得关注的地方:它把多模态、混合搜索、数据沙箱、海量逻辑表、开放计算放进一套架构里一起回答,避免把 AI 数据库收窄成向量检索
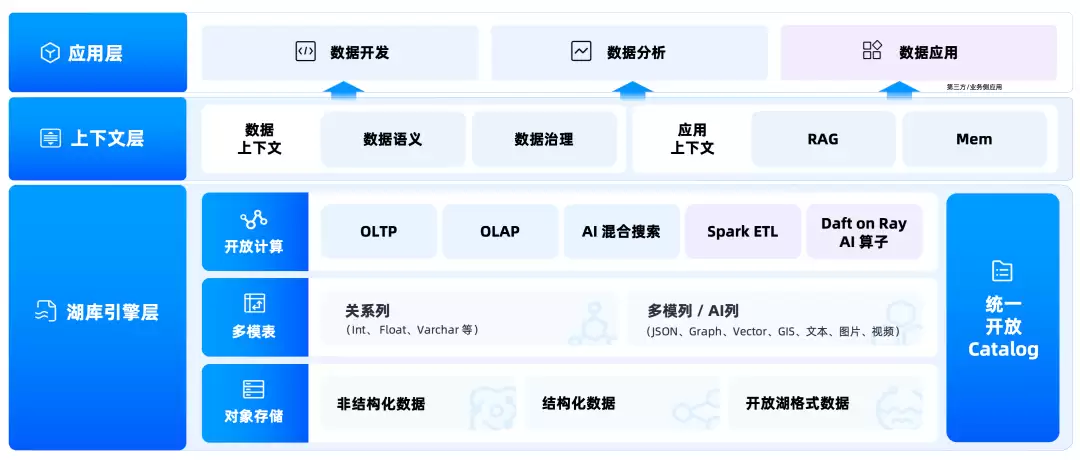
OceanBase Lakebase 是这次发布里的核心引擎
它面向湖库一体、多模态数据和 Agent 场景,目标是用一套底座统一管理结构化、半结构化、非结构化数据,同时承载 TP、AP 和 AI 工作负载
这句话听起来有点大,我理解:
企业不想再为了一个 AI 应用,同时维护交易库、数仓、对象存储、搜索引擎、向量库、权限系统、ETL 链路、RAG 服务一堆东西
Lakebase 要做的,是把关键数据底座和核心治理能力收敛起来
SQL 继续处理在线事务和查询
Spark 继续做批量加工
Ray / Daft 继续跑 AI 数据链路
对象存储、S3 兼容接口、Iceberg 开放表格式继续接入现有生态
这条路线我觉得比较现实
企业的数据平台不会一夜重建
真正可落地的路径,通常是先减少系统接缝、减少数据搬运、减少权限割裂,再慢慢把高价值场景收敛到统一底座上
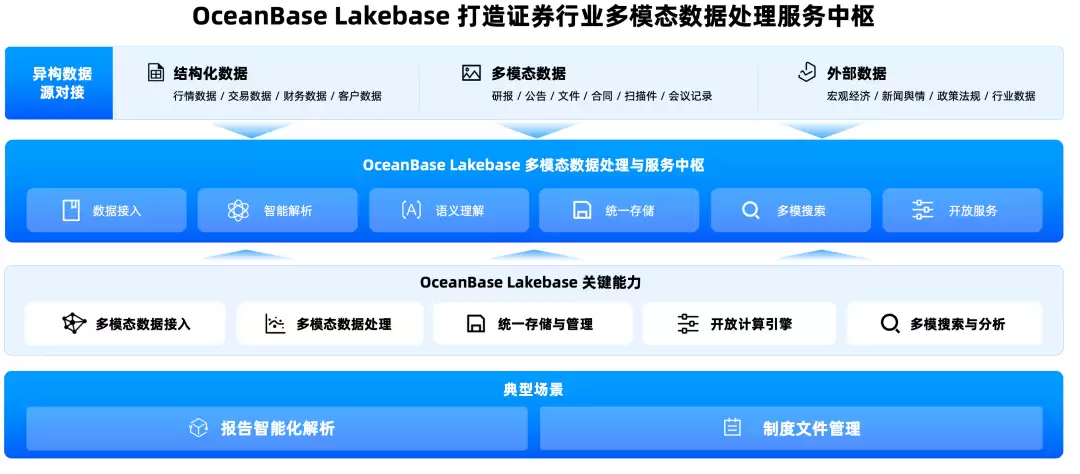
这次我最感觉最神奇的一个设计,是多模表和 AI 列
过去企业里的非结构化数据,很多时候只是附件
合同 PDF 放对象存储
图片视频放文件系统
文本摘要写业务库
向量塞进向量库
权限再单独做一套
业务上明明是同一个对象,技术上被拆成好几份
Agent 要理解它,就得从多个系统里把这些碎片拼回来
OceanBase 的多模表想解决这个问题
一张表里可以同时放结构化字段、文本、图片、音频、视频、JSON、LOB、向量
比如一张合同表,可以同时包含:
合同编号
合同 PDF
合同正文
关键条款 JSON
摘要向量
风险标签
审批状态
权限信息
用户看到的还是一张表,但这张表背后,非结构化数据已经进入同一套事务、权限、元数据、版本和生命周期管理,因为企业 AI 不缺文件,缺的是能被统一治理、统一检索、统一计算的数据资产
AI 列也很有意思,它相当于让数据库内部长出一条语义加工线,原始数据进来之后,可以在库内生成摘要、标签、特征、向量等结果,对一张表里的多行数据做 embedding 或打标,AI 列可以保证使用同一套算法,并且要么都成功,要么都失败
这句话看着朴素,但懂 RAG 的人应该很有感
向量化任务跑一半挂了,一半旧向量一半新向量,后面的召回质量会变得很玄学,数据库愿意认真处理这种一致性细节,说明它面对的是生产场景,不只是 Demo 场景

现在做企业 RAG,大家已经越来越清楚一件事:
单纯向量检索很容易翻车:语义相似,不代表业务正确,一个生产级 Agent 查资料的时候,往往要同时满足很多条件:
如果把所有候选都丢给大模型,让模型自己判断,成本高,速度慢,结果也容易飘
更好的分工应该是:数据库先做过滤、索引、权限、一致性和粗排,模型再处理真正高价值的候选,OceanBase 对混合搜索的表达挺准确:
一条 SQL 组合执行
多路召回与粗排在引擎内统一完成
模型只处理高价值候选
关系过滤、全文搜索、向量搜索、图搜索组合在一起,先把全量数据缩成候选集,再交给模型精排
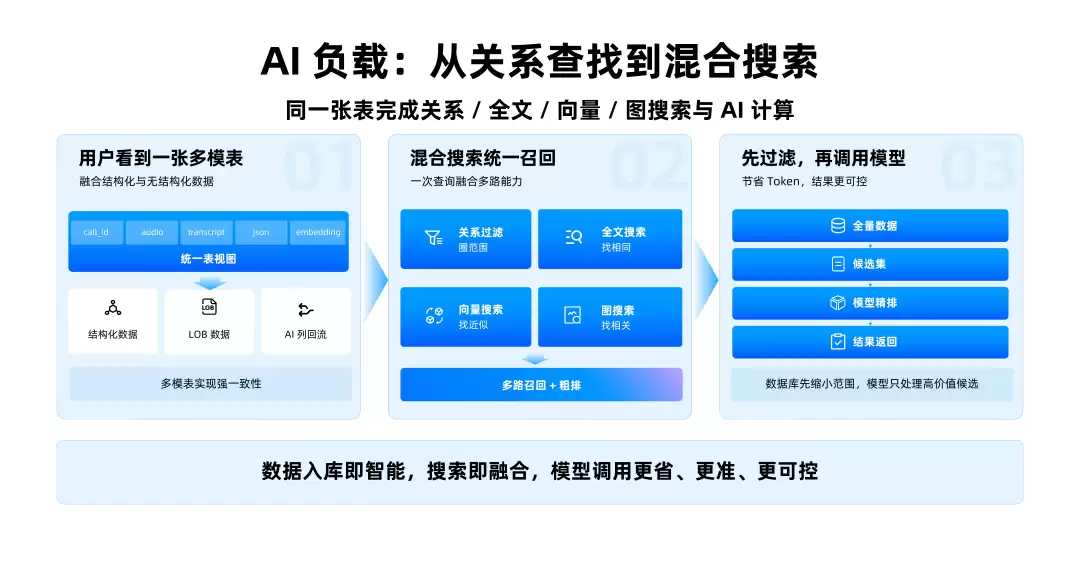
这件事并非为了炫技,解决的是企业 AI 里非常实际的问题:让上下文更准,让 token 更省,让权限更可控
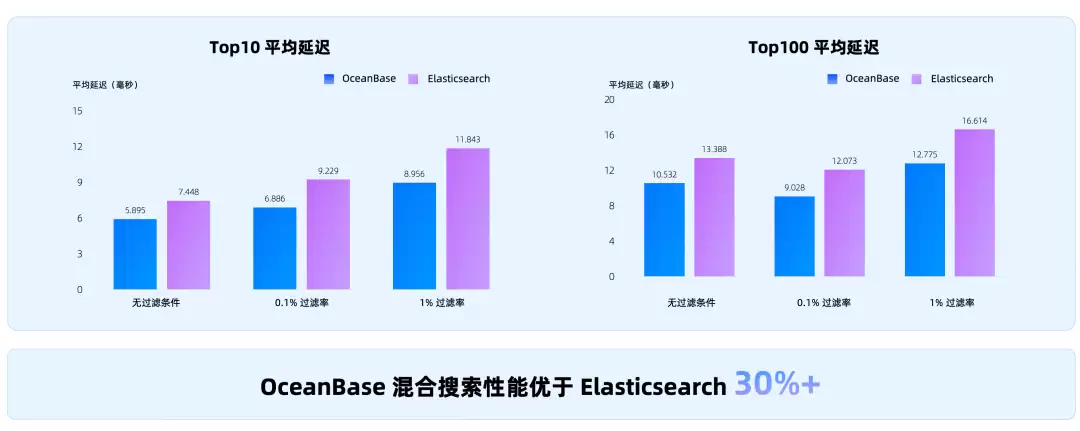
在 VectorDB Benchmark 上,同等召回率下,OceanBase 的向量性能领先于 Milvus、PGVector、Elasticsearch
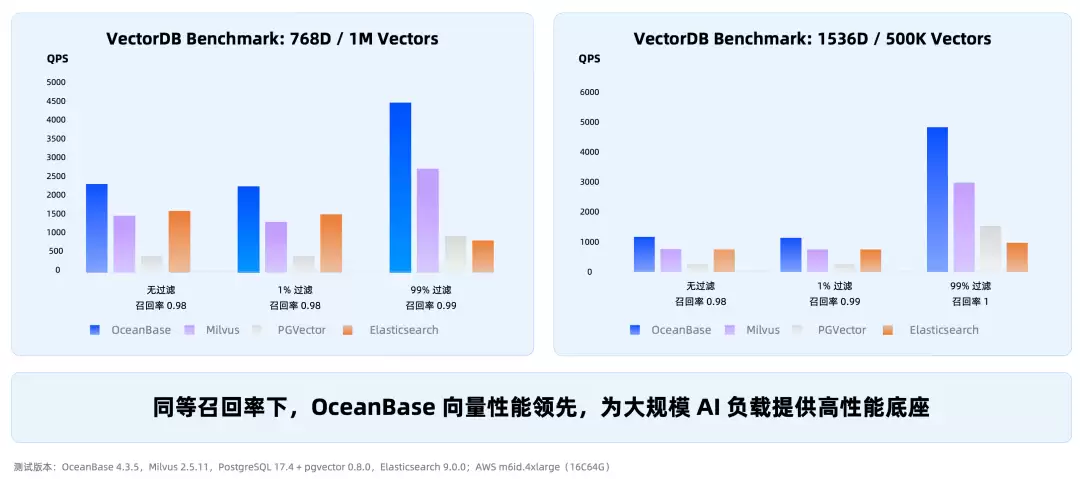
在 MSMARCO 数据集上,OceanBase 混合搜索性能优于 Elasticsearch30%+
我最近写 Agent 越多,越觉得企业真正担心的点不在“Agent 会不会干活”
它太敢干活,反而才是风险
人类工程师改库之前会备份、会评审、会问同事
Agent 很可能一边推理一边执行,直接把环境改了
所以 OceanBase 这次提到的 Fork Database、Copy-on-Write、Diff / Merge,我觉得非常关键
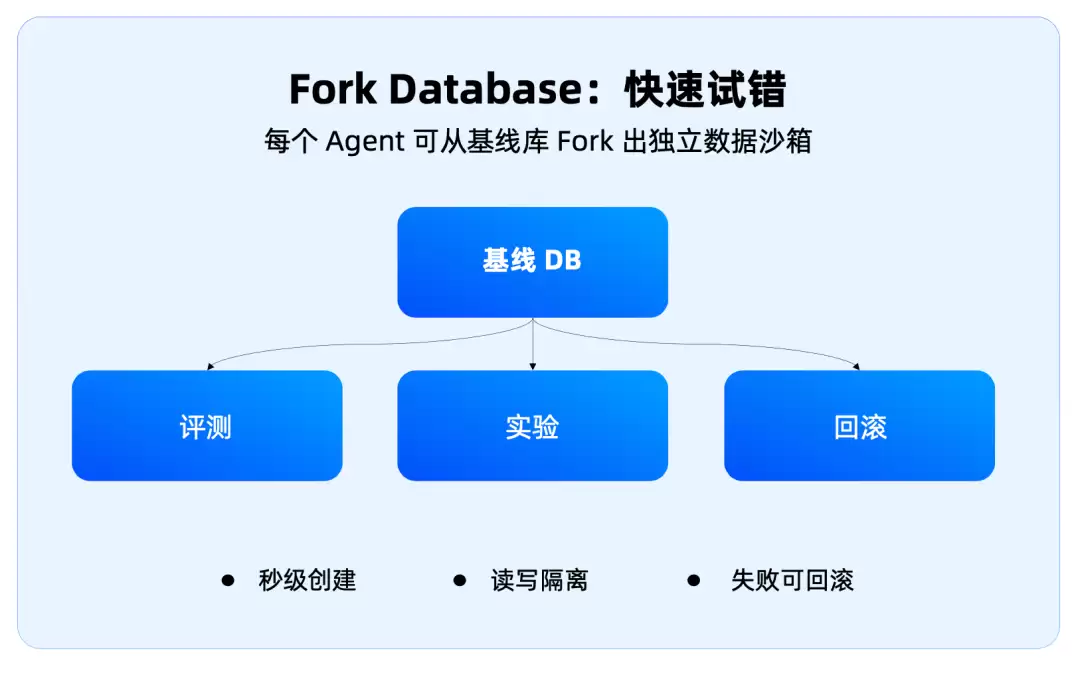
它本质上是把代码世界的分支工作流,搬进数据库世界
Fork:给 Agent 开一个独立数据沙箱
Diff:看它到底改了什么
Merge:确认没问题再合并
Rollback:失败之后快速回到原状态
比如阿福的案例
蚂蚁阿福是服务上亿用户的 AI 健康应用,回答准不准很重要,它要持续发现 bad case、修复问题、重新评估,也就是一套生产级 Agent 评测工程
问题是,评测过程会改流程、改策略、改数据
这些动作不能污染线上生产数据
为了评测稳定,又要克隆线上数据,甚至还要复制 Memory、RAG、行为数据
在 AI coding 加速之后,十几个 feature 分支以周为单位并行迭代,如果每个分支都完整复制一套环境,成本和管理复杂度都会很高
OceanBase Branch 的解法,是像代码分支一样创建数据库沙箱,它可以毫秒级创建,内部希望 5 分钟拉齐一个评测环境,用完直接销毁
Agent 改错了,就丢掉这个分支,重新从 main 拉一个出来
这才是生产级 Agent 需要的数据训练场
它的价值,是把犯错的影响圈住
Fork Database 解决单个 Agent 的安全试错,逻辑表解决海量 Agent 的低成本并行


还有个案例挺有意思
蚂蚁灵光短短几个月承载了 3000 多万个闪应用
妙思这类面向内部员工的平台,也上线了上万个应用
这些应用有一个共同点:平均每个应用表里也就百余行数据
这和过去我们理解的海量很不一样
以前说海量,往往是单库大、单表大、并发高
Agent 时代还有一种新海量:
库很多,表很多,应用很多,但每个都很小,绝大部分时间还在睡觉
99% 创建后沉睡,但要保留
少数被唤醒时,又要秒级响应
如果每个 Agent、每个轻应用都建自己的物理表,schema 会爆炸
OceanBase 给出的能力叫逻辑表
每个 Agent 看起来有独立表和独立边界,底层通过逻辑隔离把大量表收敛到共享物理资源里
再配合共享资源池、按需唤醒、闲时资源归零,才能支撑海量 Agent 低成本并行运行
我觉得这个设计很 To B
因为企业里未来不会只有一个超级 Agent
更可能是客服、财务、销售、合规、采购、研发、运营,每个部门都有一堆小 Agent、小应用、小流程
它们都需要边界
但企业不可能按每个小 Agent 一套完整数据库的成本去买单
灵光这个案例也很适合说明 Agent 时代的数据形态变化
它号称 30 秒手搓一个 AI 闪应用,但用户创建出来的应用 schema 完全不固定
一开始可以把数据全序列化成 JSON,塞进 KV 大宽表
问题来了,SUM、SORT 这些数据库算子基本用不上,只能把数据捞回业务层算,性能很差,多用户权限也难控
另一种办法是每个闪应用建一张物理表
但几千万张小表会把数据库控制面和存储打爆,灵光的方案是 OceanBase JSON Table
闪应用后端接 SDK,用户照常写标准 SQL,SDK 自动转成 JSON 写入虚拟表
用户的 SQL 不用改,OceanBase 侧继续提供索引、SUM、SORT 等能力,存储成本也能降下来,如果某个闪应用真的火了,再把这部分 JSON Table 数据迁到物理表拿更好的性能
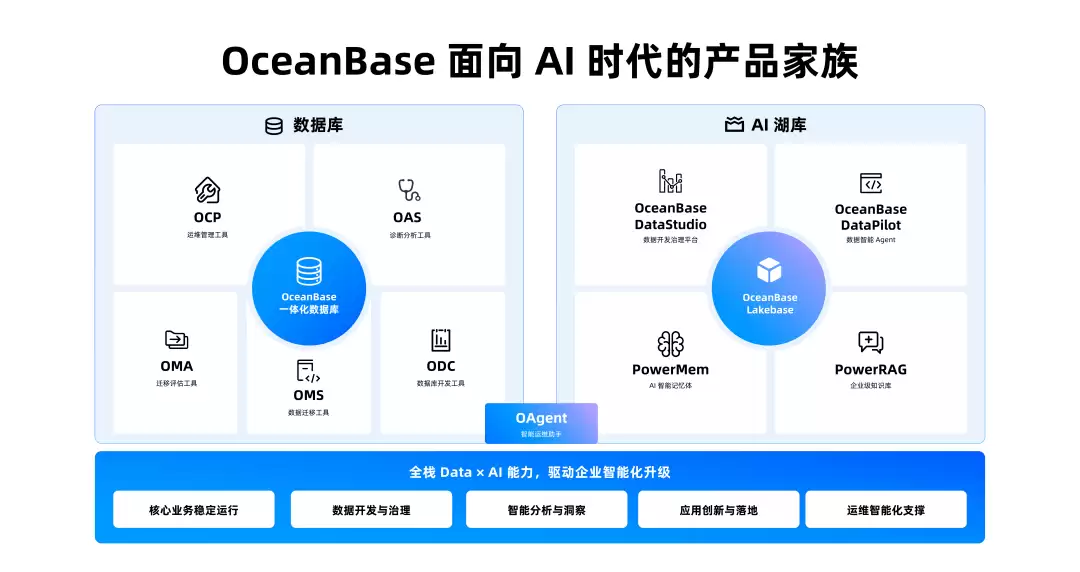
Lakebase 是底座,但 OceanBase 这次发的是一整套产品组合
完整产品体系包括:
这套组合的方向挺清楚
底层解决数据怎么存、怎么算、怎么搜
中间解决数据语义、治理、记忆和知识
上层解决业务人员怎么问数、取数、生成报告和看板
DataPilot 这一块,我觉得最适合拿给业务团队理解
业务人员不关心底层表结构,也不想等数据开发排期
他想问的是:
本月经营指标为什么波动
用户增长下降的主要原因是什么
帮我生成一个销售分析报告
搭一个经营监控看板
DataPilot 的关键远不止自然语言问数
它背后依赖业务对象、计算口径、指标定义、上下文图谱这些东西
也就是 OceanBase OSI 想解决的问题:让数据库从记录事实,往理解业务更进一步
从这张产品家族图看,OceanBase 这次讲的是从数据库到 AI 湖库的一整套能力
我会把 OceanBase 这次发布看成一个信号:
企业 AI 的竞争,正在从模型调用层,下沉到数据基础设施层
很多企业前两年忙着选模型、买算力、做知识库
下一阶段真正拉开差距的,很可能是数据底座
谁的数据更完整,谁的上下文更准,谁的权限更稳,谁的多模态数据更容易被治理,谁的 Agent 更敢进生产流程,谁就更容易做出真正能落地的 AI 应用
#OceanBase #AI数据库 #Lakebase #Agent #湖库一体
登录查看剩余 70% 内容
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]