




《猫猫钓游记》可爱+收集+钓鱼游戏试玩
2026-06-30
2026-07-05 0
2026年,随着大模型从对话框迈向智能体,公众对搜索的期待已然发生根本性转变。
搜索结果界面的首要变化直观可见:国内外两大搜索引擎均将AI生成的回答置于页面顶部,其后才是各类相关链接。
更为深层的变革在于,过往搜索产出面向人类,人们在成堆网页链接中各取所需;如今,搜索功能服务于大语言模型,只需返回一段精炼文本即可。
但这是搜索的终极形态吗?Perplexity以一篇里程碑式技术博客给出否定答案,宣称搜索将迈入第三阶段:Search as Code,即搜索即代码。
Perplexity测试显示,SaC在复杂任务上不仅全方位超越OpenAI与Anthropic,更在成本上实现近乎不可能的85%压缩。
尽管数据看似不真实,但架构背后隐藏的深度思考值得认同。
01
搜索的黄昏
自OpenAI发布大语言模型ChatGPT后,“搜索引擎”一词被提及的频率日渐稀疏。要理解SaC,首先得明白现有搜索架构为何不再适用。
如前所述,无论是谷歌还是百度,其初衷均为人类设计。人类信息接收容量与处理频率均有明确上限,因此只需直观固定的结果页。这种“输入关键词→搜索引擎黑盒处理→返回前N个结果”的单体服务模式,已统治互联网信息数十年。
大语言模型问世后,Perplexity引领了“回答引擎”风潮,通过整合提炼多篇网页内容优化信息密度,辅助模型理解、推理与生成。然而本质上,模型仍在一个预定义单向管道末端被动接收信息。
智能体时代突如其来,搜索功能的使用者由人类变为大语言模型,原有的“单体服务”模式因而成为阻碍。
如今广义智能体已远不止提问那么简单,它们需实操电脑完成任务。Perplexity内部项目的发现是,单个复杂调研任务在几分钟内可能触发成百上千次检索操作。这种高频非线性需求直接迫使传统“单体服务”面对三大挑战而濒临失效:
一是粗颗粒度的上下文:大模型对上下文极其敏感,传统“单体服务”为保证检索召回率,常塞入海量冗余信息。这种“大海捞针连带输送数十吨海水”的行为,直接导致上下文窗口迅速膨胀,进而转化为推理成本激增和幻觉频现。
二是领域知识的浪费:前沿模型本身已具备深厚“搜索经验”,知道查询知识性信息应去最新渠道而非第三方源。但在固定API检索模式下,模型的洞察力无法干预底层搜索逻辑。
三是低效对话轮次与上下文污染:传统功能调用模式下,智能体每次检索、去重、筛选均需完成“模型推理→触发工具→接收结果”的循环,这不仅累积延迟,还让上下文充斥中间态垃圾信息。Perplexity数据显示,真正有用信息常在此过程中被淹没。
02
将搜索解构
Perplexity提出的Search as Code,虽然听似抽象,但核心思路非常直接:让模型编排搜索代码,而非调用搜索接口。
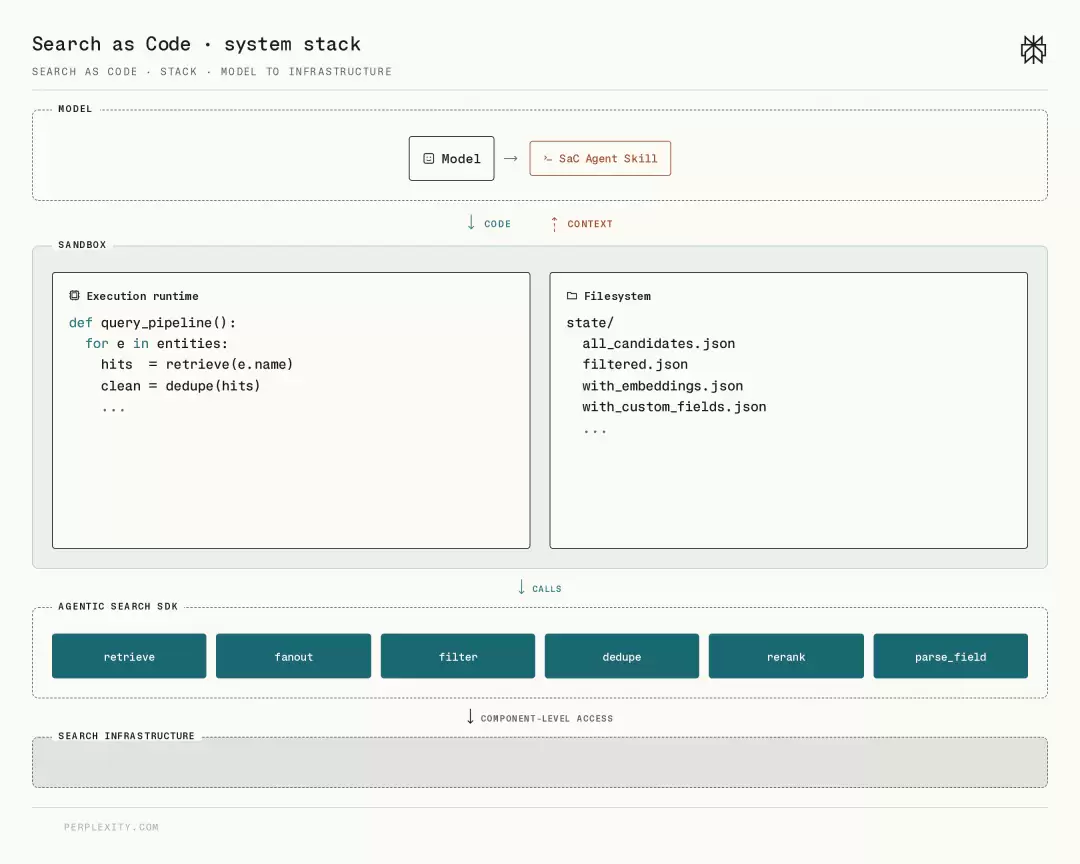
基于此,Perplexity提出“搜索即原语”。在计算机科学中,原语是不可再分解的基础构建块。SaC的目标是将原本封装在黑盒中的搜索过程拆解为初始检索、并行查询扩展、精细化过滤、去重、重排等原子组件。

为实现这些功能,SaC由三个紧密耦合的层次组成:
首先是模型层,通常采用顶尖推理能力的模型担任“指挥官”。它生成的不是文本框中的关键词,而是一段复杂Python代码。
然后是计算沙箱,提供隔离、安全、确定的执行环境。给定相同输入与代码,输出永远一致,与大语言模型的概率性生成互补。沙箱负责执行循环、重试、数据聚合等操作,无需大语言模型干预。
最后是原子化SDK,这是SaC架构的灵魂,提供一组完成retrieve、dedupe、rerank的“专用手柄”。Perplexity未简单封装旧API,而是重构搜索堆栈,使SDK能直接操作搜索系统内部状态。
回到用户视角,原先搜索结果中的一行行网页链接,可能按关键词匹配、时效性或权威性排列。只要黑盒不打开,排序逻辑始终未知。而在SaC架构下,模型能查看各种后台数据,并根据任务需求应用最有价值的搜索结果。
03
底层工程的博弈
如果说三层架构是SaC的骨架,那么沙箱内部的工程决策,则是决定其能否在现实世界中稳定运行的灵魂。
设计执行环境时,Perplexity并未盲目追求指标高性能,而是深入探讨了两个代表性技术权衡:
一是语言博弈。选择沙箱运行语言时,团队面临两难:执行效率高的Rust,还是类型严密的TypeScript?出人意料的是,最终选择了Python——大语言模型的“母语”。理由在于Python拥有近乎无敌的数据处理生态,如NumPy和Pandas。同时,大语言模型在预训练阶段对Python代码的理解与生成能力最强,可显著提升代码生成质量。
二是状态博弈。第二个决策关乎智能体如何记忆中间数据。当智能体执行以小时为单位的长程任务时,会产生海量中间检索结果,这些数据如何保存?团队面前有两种方案:REPL模式,类似Jupyter Notebook,变量始终在内存中,模型随时取用;文件系统序列化模式,要求模型显式将数据转换为JSON格式写入沙箱磁盘。REPL模式看似方便,但在处理长路径任务时是陷阱。随着任务进行,内存中充斥大量临时变量,导致命名空间污染,模型后续步骤发生混乱。因此,Perplexity选择繁琐的文件系统序列化,每一步处理数据后,必须以“声明式”严谨态度明确打包、贴标签并存入磁盘。这属于工程上的“强约束”,虽让模型多写几行代码,却极大提升智能体执行复杂任务时的逻辑清晰度和可追溯性。
04
性能与性价比的兼顾
Perplexity研究不止于理论,他们发布了全新基准测试,并建立了一套“成本-性能边界”评估体系,与当下主流AI测评体系一致,强调性价比而非单纯性能领先。
WANDR基准是Perplexity设计的专门模拟复杂、高宽度专业调研任务的测试。在此基准中,SaC表现几乎达到第二名Opus 4.7的2.5倍。面对需跨越多个信息源、持续数小时的复杂任务,传统“对话式搜索”已彻底失效,而SaC的代码驱动逻辑体现出统治级效率。
同时,Perplexity重新定义搜索性价比。他们引用经济学术语“帕累托边界”,指在不损害其他目标时无法进一步优化某一目标。SaC在低、中、高三种推理强度配置下,竟奇迹般位于最优边界之上。
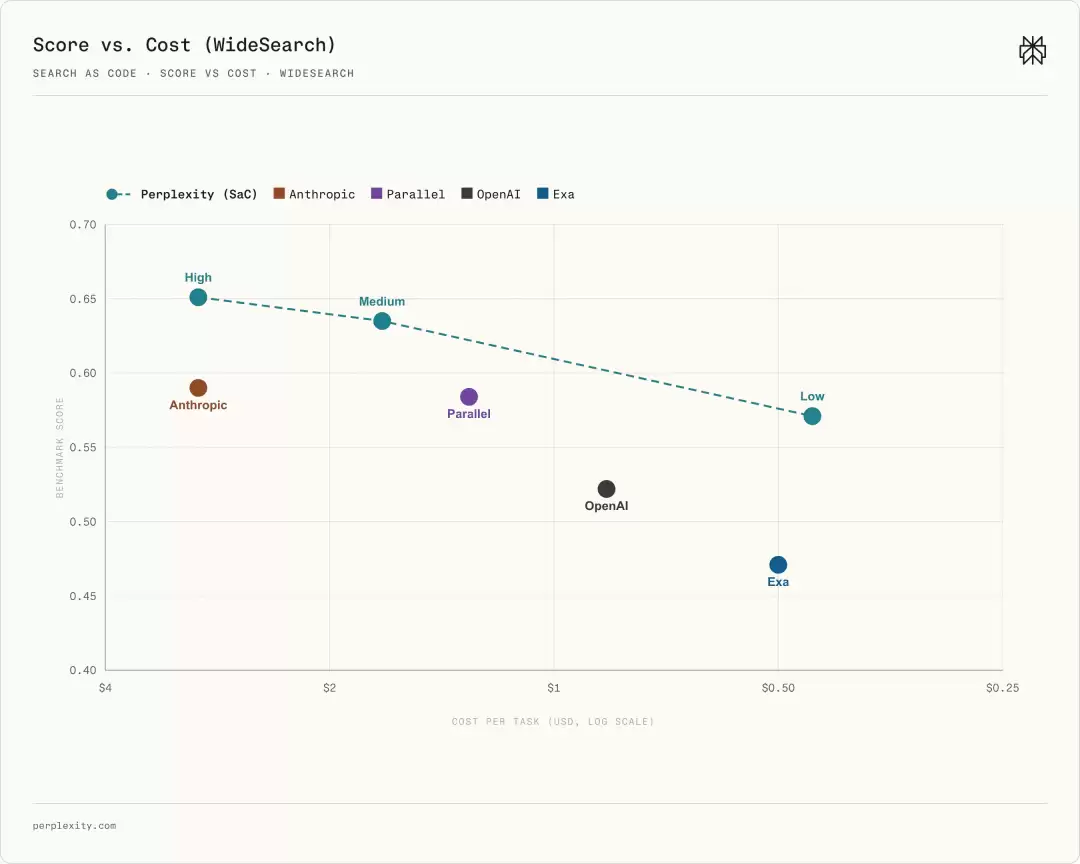
低推理强度下,其价格低于纯API检索,表现优于部分竞争对手;中推理强度下,单次任务成本1美元以内时,SaC架构已对其他架构实现全面超越。
客观而言,Perplexity展示数据均源于自建评估体系,难免受“自卖自夸”质疑。但重要的是,这些数据验证了AI发展规律转变:搜索效率正从增加模型参数转向优化架构编排。
05
未来的计算架构
Perplexity这篇技术博客结尾极具思想深度。Search as Code不仅是一句商业化口号,还反映了软件设计的一场宏大变革。
计算机科学历史中存有两种截然不同的计算形式:一种是确定性指令,运行在CPU上,逻辑严密,适合批处理、排序和并行化;另一种是token空间推理,即大模型独有能力,擅长处理不确定性、理解语义并制定策略。SaC的真正意义正是这两种计算形式的完美结合。模型意味着需决定“需要什么证据”及“如何解决矛盾”;代码与沙箱则是确定的,负责处理海量繁重的I/O操作与逻辑过滤。
Perplexity甚至提出更前沿的联合设计构想:未来模型可能不再“学会”写代码,而是在训练阶段与SDK共同进化,直接理解低层级搜索信号。
这篇技术博客可视为给所有智能体开发者的路线图。若开发者仍在为智能体设计搜索插件,那便是重复造轮子。Search as Code,搜索不应是终点,而是一个可被模型自由操控、无限透明的过程。当“搜索即代码”成为智能体标配,其上限将不再受限于“看到什么”,而取决于“如何寻找”。
Search as Code将搜索转化为可被模型自由操控的透明过程,这一架构变革或许正是通往AGI的必经之路。
Copyright(C) 2020-2026 jiyx.com All Rights Reserved 联系方式:[email protected]